Aprender um idioma pode abrir novas oportunidades na vida de uma pessoa. Pode ajudar as pessoas a se conectarem com pessoas de diferentes culturas, viajarem pelo mundo e progredirem em suas carreiras. Estima-se que só o inglês tenha 1,5 bilhão de alunos em todo o mundo. No entanto, é difícil alcançar a proficiência numa nova língua e muitos alunos citam a falta de oportunidade de praticar a fala ativamente e de receber feedback acionável como uma barreira à aprendizagem.
Temos o prazer de anunciar um novo recurso da Pesquisa Google que ajuda as pessoas a praticar a fala e a melhorar suas habilidades no idioma. Nos próximos dias, os usuários do Android na Argentina, Colômbia, Índia (hindi), Indonésia, México e Venezuela poderão obter ainda mais suporte linguístico do Google por meio da prática interativa de conversação em inglês, expandindo-se para mais países e idiomas no futuro. A Pesquisa Google já é uma ferramenta valiosa para alunos de idiomas, fornecendo traduções, definições e outros recursos para melhorar o vocabulário. Agora, os alunos que traduzem para ou do inglês em seus telefones Android encontrarão uma nova experiência prática de língua inglesa com feedback personalizado.
 |
| Um novo recurso da Pesquisa Google permite que os alunos pratiquem a fala de palavras no contexto. |
Os alunos recebem instruções da vida real e, em seguida, formam suas próprias respostas faladas usando uma palavra do vocabulário fornecida. Eles participam de sessões práticas de 3 a 5 minutos, recebendo feedback personalizado e a opção de se inscrever para receber lembretes diários para continuar praticando. Com apenas um smartphone e algum tempo de qualidade, os alunos podem praticar no seu próprio ritmo, a qualquer hora e em qualquer lugar.
Atividades com feedback personalizado, para complementar as ferramentas de aprendizagem existentes
Projetado para ser usado junto com outros serviços e recursos de aprendizagem, como aulas particulares, aplicativos móveis e aulas, o novo recurso de prática de conversação na Pesquisa Google é outra ferramenta para ajudar os alunos em sua jornada.
Fizemos parcerias com linguistas, professores e ESL/EFL especialistas pedagógicos para criar uma experiência prática de conversação que seja eficaz e motivadora. Os alunos praticam o vocabulário em contextos autênticos e o material é repetido em intervalos dinâmicos para aumentar a retenção — abordagens que são conhecidas por serem eficazes para ajudar os alunos a se tornarem falantes confiantes. Como um parceiro nosso compartilhou:
“Falar em um determinado contexto é uma habilidade que os alunos de línguas muitas vezes não têm oportunidade de praticar. Portanto esta ferramenta é muito útil para complementar aulas e outros recursos.” – Judit Kormos, professora, Universidade de Lancaster
Também estamos entusiasmados por trabalhar com vários parceiros de aprendizagem de idiomas para divulgar o conteúdo que eles estão ajudando a criar e conectá-los com alunos de todo o mundo. Esperamos expandir ainda mais este programa e trabalhar com qualquer parceiro interessado.
Feedback personalizado em tempo real
Cada aluno é diferente, portanto, fornecer feedback personalizado em tempo real é uma parte fundamental da prática eficaz. As respostas são analisadas para fornecer sugestões e correções úteis em tempo real.
O sistema fornece feedback semântico, indicando se a resposta foi relevante para a pergunta e se pode ser compreendida por um interlocutor. Feedback gramatical fornece insights sobre possíveis melhorias gramaticais e um conjunto de exemplos de respostas em vários níveis de complexidade linguística, dão sugestões concretas sobre formas alternativas de responder neste contexto.
 |
| O feedback é composto por três elementos: análise semântica, correção gramatical e exemplos de respostas. |
Tradução contextual
Entre as diversas novas tecnologias que desenvolvemos, a tradução contextual oferece a capacidade de traduzir palavras e frases individuais no contexto. Durante as sessões práticas, os alunos podem tocar em qualquer palavra que não entendem para ver a tradução dessa palavra considerando seu contexto.
 |
| Exemplo de recurso de tradução contextual. |
Esta é uma tarefa técnica difícil, uma vez que palavras individuais isoladas muitas vezes têm múltiplos significados alternativos, e múltiplas palavras podem formar grupos de significados que precisam ser traduzidos em uníssono. Nossa nova abordagem traduz a frase inteira e, em seguida, estima como as palavras do texto original e do texto traduzido se relacionam entre si. Isso é comumente conhecido como problema de alinhamento de palavras.
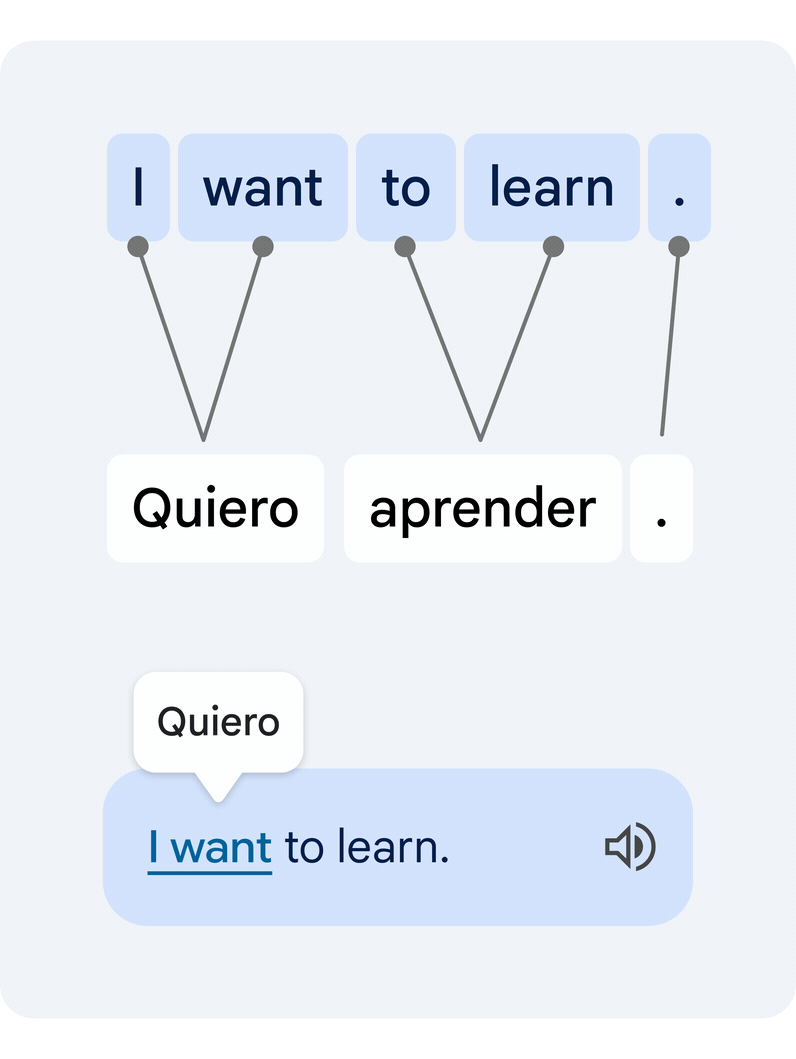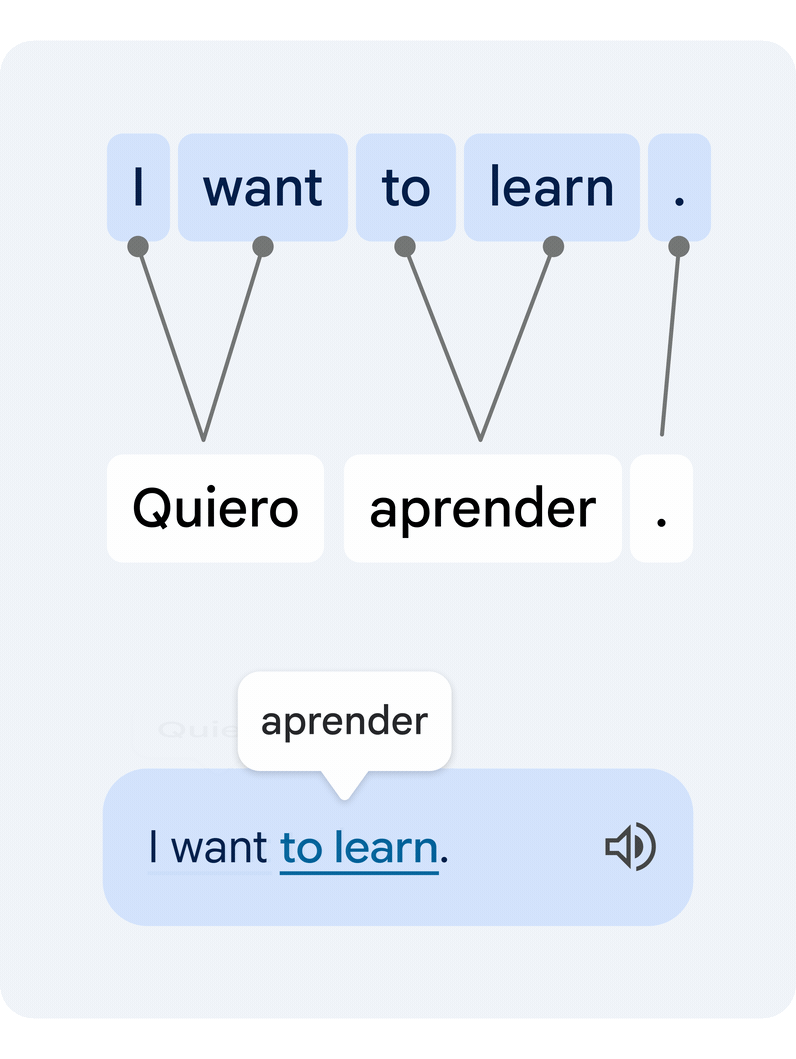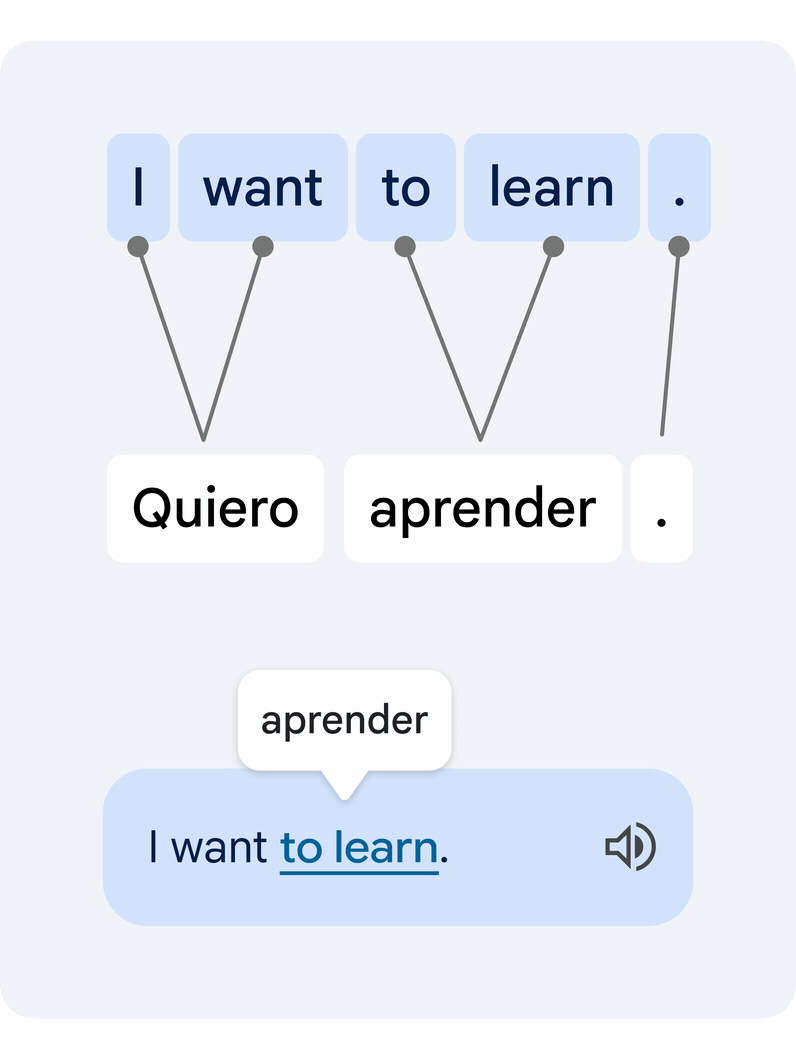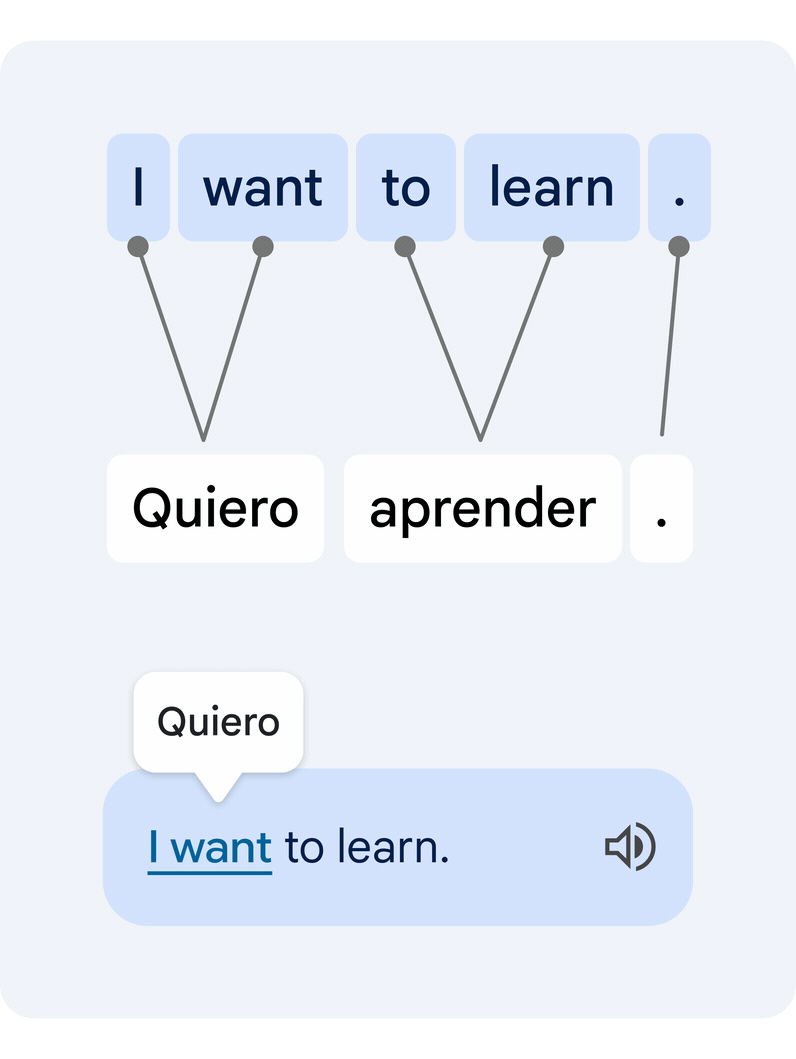 |
| Exemplo de um par de frases traduzidas e seu alinhamento de palavras. Um modelo de alinhamento de aprendizagem profunda conecta as diferentes palavras que criam o significado para sugerir uma tradução. |
A principal peça tecnológica que permite essa funcionalidade é um novo modelo de aprendizado profundo desenvolvido em colaboração com a equipe do Google Tradutor, chamado Deep Aligner. A ideia básica é pegar um modelo de linguagem multilíngue treinado em centenas de idiomas e, em seguida, ajustar um novo modelo de alinhamento em um conjunto de exemplos de alinhamento de palavras (veja um exemplo na figura acima) fornecidos por especialistas humanos, para vários pares de idiomas. A partir disso, o modelo único pode alinhar com precisão qualquer par de idiomas, atingindo a taxa de erro de alinhamento de última geração (AER, uma métrica para medir a qualidade dos alinhamentos de palavras, onde menor é melhor). Este novo modelo único levou a melhorias drásticas na qualidade do alinhamento em todos os pares de idiomas testados, reduzindo o AER médio de 25% para 5% em comparação com abordagens de alinhamento baseadas em modelos ocultos de Markov< a i=4> (HMMs).
 |
| Taxas de erro de alinhamento (quanto menor, melhor) entre o inglês (EN) e outros idiomas. |
Esse modelo também é incorporado às APIs de tradução do Google, melhorando muito, por exemplo, a formatação de PDFs e sites traduzidos no Chrome, a tradução de legendas do YouTube e aprimorando a API de tradução do Google Cloud.
Feedback gramatical
Para permitir feedback gramatical para linguagem falada com sotaque, nossas equipes de pesquisa adaptaram modelos de correção gramatical para texto escrito (veja o blog e paper) para trabalhar em transcrições de reconhecimento automático de fala (ASR), especificamente para o caso de fala com sotaque. A etapa principal foi o ajuste fino do modelo de texto escrito em um corpus de transcrições humanas e ASR de fala com sotaque, com correções gramaticais fornecidas por especialistas. Além disso, inspiradas em trabalhos anteriores, as equipes desenvolveram uma nova representação de resultados baseada em edição que aproveita a alta sobreposição entre as entradas e os resultados, o que é particularmente bem-sucedido. adequado para frases curtas comuns em ambientes de aprendizagem de línguas.
A representação de edição pode ser explicada usando um exemplo:
- Entrada: I1 sou2 cozinhando54 mal3 então
- Correção: I1 sou2 em6 cozinhando54 ruim3 então
- Edições: (‘at’, 4, PREPOSIÇÃO, 4)
Acima, “at” é a palavra inserida na posição 4 e “PREPOSIÇÃO” denota que se trata de um erro envolvendo preposições. Usamos a tag de erro para selecionar limites de aceitação dependentes da tag que melhoraram ainda mais o modelo. O modelo aumentou a recordação de problemas gramaticais de 4,6% para 35%.
Alguns exemplos de resultados de nosso modelo e de um modelo treinado em corpora escritos:
| Exemplo 1 | Exemplo 2 | |||
| Entrada do usuário (fala transcrita) | Vivo da minha profissão. | Preciso de um cartão eficiente e confiável. | ||
| Modelo gramatical baseado em texto | Eu vivo da minha profissão. | Preciso de um cartão eficiente e confiável. | ||
| Novo modelo otimizado para fala | Vivo da minha profissão. | Preciso de um cartão eficiente e confiável. |
Análise semântica
O objetivo principal da conversa é comunicar claramente a intenção. Assim, projetamos um recurso que comunica visualmente ao aluno se sua resposta era relevante para o contexto e se seria compreendida por um parceiro. Este é um problema técnico difícil, uma vez que as respostas faladas dos primeiros alunos de línguas podem ser sintaticamente não convencionais. Tivemos que equilibrar cuidadosamente essa tecnologia para focar na clareza da intenção, e não na correção da sintaxe.
Nosso sistema utiliza uma combinação de duas abordagens:
- Classificação de Sensibilidade: modelos de linguagem grandes como LaMDA ou Os PaLM são projetados para fornecer respostas naturais em uma conversa, por isso não é surpresa que eles tenham um bom desempenho no sentido inverso: julgar se uma determinada resposta é contextualmente sensata.
- Similaridade com boas respostas: usamos uma arquitetura de codificador para comparar a entrada do aluno com um conjunto de boas respostas conhecidas em um espaço de incorporação semântica. Essa comparação fornece outro sinal útil sobre a relevância semântica, melhorando ainda mais a qualidade do feedback e das sugestões que fornecemos.
 |
| O sistema fornece feedback sobre se a resposta foi relevante para a solicitação e se seria compreendida por um parceiro de comunicação. |
Desenvolvimento de conteúdo assistido por ML
Nossas atividades práticas disponíveis apresentam uma mistura de conteúdo criado por especialistas humanos e conteúdo criado com assistência de IA e revisão humana. Isso inclui instruções faladas, palavras focais, bem como conjuntos de exemplos de respostas que mostram respostas significativas e contextuais.
 |
| Uma lista de exemplos de respostas é fornecida quando o aluno recebe feedback e quando toca no botão de ajuda. |
Como os alunos têm diferentes níveis de habilidade, a complexidade linguística do conteúdo deve ser ajustada de forma adequada. Trabalhos anteriores sobre estimativa de complexidade de linguagem concentram-se em textos com comprimento de parágrafo ou mais longos , o que difere significativamente do tipo de respostas que nosso sistema processa. Assim, desenvolvemos novos modelos que podem estimar a complexidade de uma única frase, frase ou mesmo palavras individuais. Isto é um desafio porque mesmo uma frase composta por palavras simples pode ser difícil para um aluno de línguas (por exemplo, “Vamos direto ao ponto”). Nosso melhor modelo é baseado em BERT e atinge previsões de complexidade mais próximas do consenso de especialistas humanos. O modelo foi pré-treinado usando um grande conjunto de exemplos rotulados como LLM e, em seguida, ajustado usando um conjunto de dados rotulado por especialistas humanos.
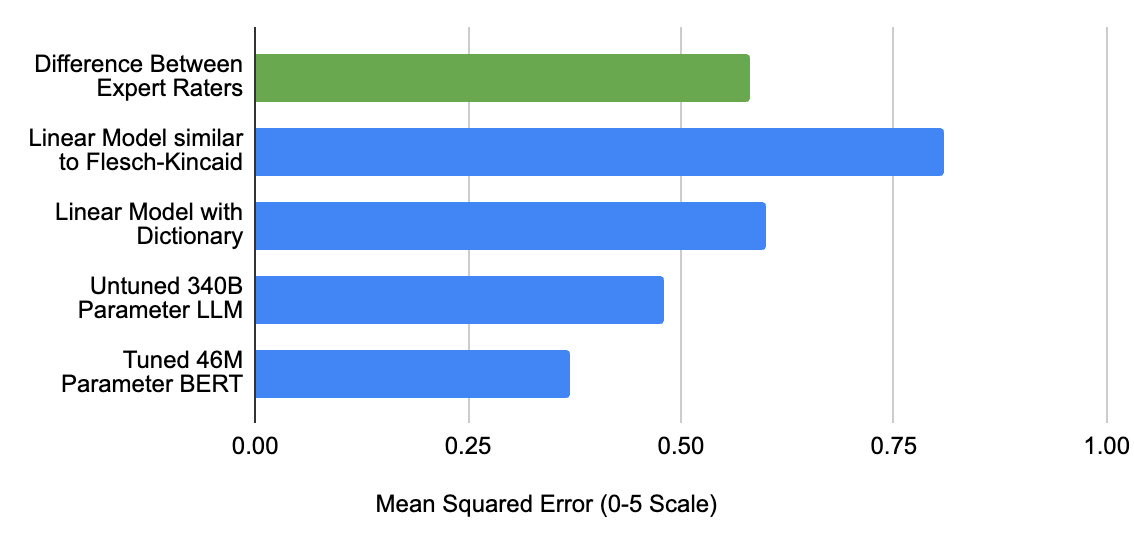 |
| Erro quadrático médio do desempenho de várias abordagens estimando a dificuldade do conteúdo em um corpus diversificado de aproximadamente 450 passagens de conversação (texto/transcrições). Linha superior: Os avaliadores humanos rotularam os itens em uma escala de 0,0 a 5,0, aproximadamente alinhada à escala CEFR< /span>: modelos diferentes executaram a mesma tarefa e mostramos a diferença para o consenso de especialistas humanos.Quatro linhas inferiores (de A1 a C2). |
Usando este modelo, podemos avaliar a dificuldade dos itens de texto, oferecer uma gama diversificada de sugestões e, o mais importante, desafiar os alunos de forma adequada aos seus níveis de habilidade. Por exemplo, usando nosso modelo para rotular exemplos, podemos ajustar nosso sistema para gerar instruções faladas em vários níveis de complexidade linguística.
| Palavras focais do vocabulário, a serem suscitadas pelas perguntas | ||||||
| guitarra | maçã | leão | ||||
| Simples | O que voce gosta de jogar? | Você gosta de fruta? | Você gosta de gatos grandes? | |||
| Intermediário | Você toca algum instrumento musical? | Qual é a sua fruta favorita? | Qual é o seu animal favorito? | |||
| Complexo | Que instrumento de cordas você gosta de tocar? | Que tipo de fruta você gosta de comer por sua textura crocante e sabor adocicado? | Você gosta de assistir predadores grandes e poderosos? | |||
Além disso, a estimativa da dificuldade do conteúdo é utilizada para aumentar gradualmente a dificuldade da tarefa ao longo do tempo, adaptando-se ao progresso do aluno.
Saiba mais no https://unknownsunknowns.com/





