Como o Hurb usa Machine Learning para escolher as melhores opções de voo para os clientes
Conheça como o Hurb utiliza a tecnologia para melhorar os processos e a experiência do cliente por meio de um projeto de machine learning de ponta a ponta.
Atualmente o principal produto que comercializamos são os pacotes mês fixo , que são compostos por dois elementos principais: a hospedagem e a passagem aérea até o destino. Oferecemos ótimas ofertas aos nossos clientes, vendendo pacotes para viagens com seis ou mais meses de antecedência.
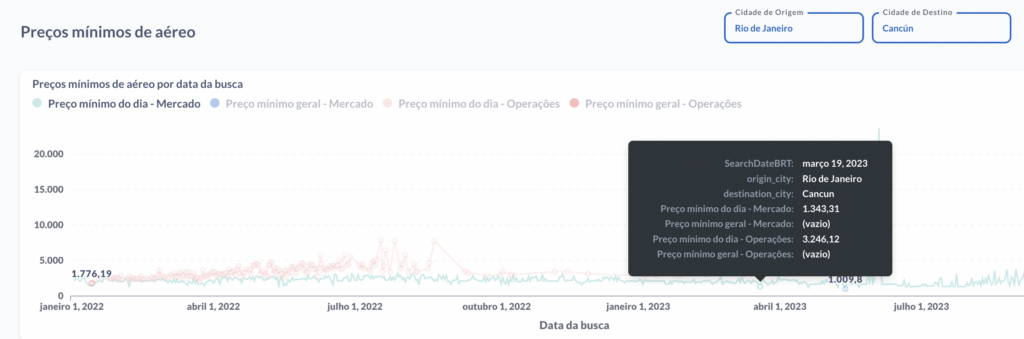
Dentro deste intervalo de tempo, entre a compra e a data da viagem, nosso algoritmo desenvolvido in house faz 250 milhões de buscas por dia efetuando a reserva nos micro-segundos onde os preços se encontram na mínima (há uma grande volatilidade nos preços) conseguimos encontrar o melhor momento para adquirir as passagens e hospedagem, negociando com companhias aéreas e hotéis, bem como utilizando a tecnologia para explorar as oscilações de preços de mercado. Abaixo segue um exemplo de pacote onde o cliente pode viajar em 2024, exceto feriados e períodos de alta temporada. Como no exemplo abaixo onde na data de 19/03/2023 a passagem Rio-Cancun teve o preço mínimo de R$1.343,31 e o preço médio do dia R$3.246,12
Embora as datas dos pacotes sejam flexíveis, o cliente ainda tem algum controle sobre quando irá viajar. Enviamos um formulário solicitando três sugestões de datas em que desejam viajar e tentaremos alocá-las dentro dessas datas ou o mais próximo possível dessas datas (desde que encontremos boas ofertas nessas datas). Encontrar a melhor passagem aérea para o cliente é um desafio, precisamos considerar vários fatores, como: as preferências dos clientes (viajar de manhã ou à noite, disponibilidade de espera por longas conexões), garantir que o preço das passagens aéreas se ajuste nosso orçamento e também as próprias restrições do destino. Por exemplo, Morro do São Paulo é um destino em uma ilha, então o cliente precisa chegar a tempo de pegar o barco até a ilha antes do anoitecer.
Assim que encontrarmos uma passagem aérea adequada para o cliente, nós a enviaremos para que ele aceite ou recuse. Caso eles recusem, temos que encontrar outra opção de passagem aérea para eles e reenviar até que aceitem, o que gera muito retrabalho, custos e também seria prejudicial à experiência do cliente. Quando o cliente rejeita mais de 3 opções, o Hurb negocia outras datas dentro da validade do pacote ou solicita ao cliente o cancelamento do pedido. Além disso, até o desenvolvimento do modelo, os critérios sobre o que é uma passagem aérea adequada eram subjetivos e dependiam do especialista em viagens.
Para aumentar nossa eficiência e reduzir esse retrabalho, desenvolvemos uma solução de aprendizado de máquina que nos dá a probabilidade de um cliente aceitar uma determinada opção de voo com base nos clientes e nas informações do voo.
Solução
Conforme mencionado acima, o objetivo era minimizar o retrabalho e maximizar a satisfação do cliente, aumentando a taxa de aceitação de voos através de uma solução que nos dá a probabilidade de um cliente aceitar uma opção de voo para que possamos tomar melhores decisões e reduzir a incerteza.
O primeiro passo foi alinhar expectativas e entender o problema do negócio, resolvendo questões como:
- Como o modelo seria usado e implementado?
- Existe alguma restrição que precisamos considerar, como latência?
- Quais são as possíveis entradas do modelo?
- Como o modelo deve ser entregue? Como uma API?
- Como o modelo será avaliado? Temos uma linha de base?
- O que seria um MVP?
Então começamos a explorar os dados disponíveis. Já tínhamos anos de dados de opções de voos anteriores enviados manualmente aos clientes e seu resultado (aceito ou recusado). Portanto, tínhamos um problema de classificação em mãos!
Começámos por avaliar os dados através de uma análise exploratória de dados, que incluiu:
- Compreender outliers para encontrar a melhor estratégia para lidar com eles;
- Compreender a distribuição dos dados numéricos;
- Compreender proporções das variáveis categóricas e sua cardinalidade;
- Compreender as correlações entre as variáveis;
- Que possível viés os dados poderiam ter?
- Encontrar a linha de base humana histórica para o problema.
Os dados históricos que tínhamos já eram conhecidos por terem um viés. Tivemos apenas as opções enviadas ao cliente, que já tinha filtros de especialistas em viagens aplicados. Não era o ideal, o melhor seria ter todas as opções possíveis mostradas ao especialista em viagens e alguma bandeira para identificar qual escolheu enviar, para que pudéssemos entender o padrão por trás da seleção de opções da operadora. Foi declarado como possível melhoria futura, é muito importante documentá-lo.
A engenharia de recursos também foi necessária para obter os recursos necessários, como obter conexão e tempo de viagem, extrair partes de data, extrair timedeltas e muito mais.
Em seguida utilizamos PCA (Análise de Componentes Principais) para entender se as características escolhidas se comportam de forma linear e tentamos separar visualmente as classes. Foi surpreendente encontrarmos um sinal positivo em relação à sua linearidade e podermos visualizar as classes, o que também significou que estávamos no caminho certo para resolver o problema.
A fase de experimentação também testou essa hipótese, na qual testamos diversos algoritmos diferentes, como Regressão Logística, Catboost e Redes Neurais. Tudo hiperajustado usando a estratégia de busca bayesiana.
Conforme constatado na fase exploratória de análise de dados, também estávamos lidando com conjuntos de dados desequilibrados. Portanto, também testamos o uso de estratégias de subamostragem e sobre amostragem, bem como o balanceamento das classes usando pesos.
Além disso, experimentamos diferentes seleções e engenharia de recursos, como o uso de transformação sen/cos em recursos cíclicos ou bucketização e tratamento como categórico. Além disso, experimentamos diferentes transformações categóricas, como um codificador quente e um codificador médio e muito mais.
MLFlow foi usado para rastrear todos os experimentos, salvando parâmetros, hiperparâmetros, métricas, conjuntos de dados, recursos, gráficos e muito mais. Isso foi essencial, pois experimentamos muitas configurações diferentes e precisávamos recuperar esses dados posteriormente para comparar os experimentos.
O projeto visa minimizar o retrabalho. Supondo que se o modelo prevê que o cliente irá rejeitar a opção, não enviaremos, então a única situação em que teríamos que retrabalhar seria o modelo prevendo que o cliente aceitaria, mas acabou rejeitando. Pensando nisso, podemos relacioná-lo com a precisão, onde o rótulo positivo seria a opção aceita. Podemos então assumir que a precisão seria a nossa taxa de aceitação de voos, que é uma métrica de negócio já conhecida e representa o que queremos maximizar. Agora podemos comparar e avaliar nossos experimentos.
Alcançamos ótimos resultados com os experimentos. Comparamos a precisão entre eles e também analisamos a distribuição do preço das passagens aéreas daquelas que o modelo previa como recusadas, mas foram aceitas. Isso foi feito para entender a oportunidade perdida, por isso escolhemos o modelo que tinha a melhor precisão sem muitas oportunidades perdidas.
Por fim, para testar o modelo, fizemos um shadow implantation de 3 meses, através do qual observamos um desempenho inferior do modelo comparado ao desempenho do teste durante a fase de treinamento. Era esperado, mas para entender melhor esse comportamento, também verificamos o desvio de dados usando o teste exato de Fisher, o teste de Kolmogorov-Smirnov e algumas abordagens de desvio de dados adversários. Identificamos muitos desvios de dados, que incluíram:
- Novos destinos, que ainda não operamos;
- Alteração na distribuição dos dados devido à alteração na proporção de destinos nacionais e internacionais;
- Operamos clientes que viajarão com alguns meses de antecedência. Portanto, será sempre um subconjunto do treinamento utilizado para avaliar o modelo em produção.
Verificamos com a equipe de operações alguns desvios de dados e percebemos que funcionavam de forma diferente ao longo da semana, algumas semanas eram focadas na emissão, outras nas opções de envio. Portanto, o desvio de dados também dependia de como a equipe estava operando e poderia ser dinâmico.
Portanto, concluímos que a cada mês ainda teríamos algum desvio para lidar. Porém, como vimos, mesmo com o desvio de dados, o modelo ainda era bom o suficiente, acima do limite de produção. Além disso, após reportarmos os resultados aos stakeholders, eles concordaram conosco e aprovaram o modelo.
Implementação
Desenvolvemos a API utilizando o pacote BentoML, que abstrai e empacota o modelo. Em seguida, construímos e implantamos a imagem docker BentoML no Vertex AI. Posteriormente, implementamos e implantamos o modelo em um endpoint usando Vertex AI também.
BentoML é ótimo para abstrair e acelerar o desenvolvimento de APIs. Vertex AI é uma ferramenta excelente e intuitiva para dimensionar e implantar o modelo, os modelos também são versionados dentro do Vertex AI e também podemos testar modelos A/B, o que é uma funcionalidade muito útil.

Agora temos um endpoint que a equipe de operações pode usar para passar as entradas alinhadas e recuperar as probabilidades de aceitação. Foi integrado ao fluxo de trabalho de operações, que recupera as melhores passagens aéreas, verifica se o preço está dentro do limite orçamentário daquela rota e busca os clientes com maior probabilidade de aceitar aquela opção e envia automaticamente se estiver acima de um limite.
Embora não tenhamos observado grande aumento na taxa de aceitação de voos desde a implantação do modelo, tivemos um grande aumento na eficiência da operação, pois ajudou a automatizar parte do processo. Agora podemos escalar nossas operações e enviar mais opções ao cliente.
Manutenção
A implantação não é a última etapa! Temos que monitorar continuamente o modelo para garantir que ele ainda esteja funcionando conforme o esperado, uma vez que os modelos provavelmente ficarão obsoletos com o tempo.
Portanto, criamos dois fluxos de trabalho principais que são executados automaticamente e orquestrados pela ferramenta Flyte que roda em Kubernetes:
- Monitore mensalmente o desempenho do modelo nos dois meses anteriores. Isso porque há períodos que o volume da nossa operação diminui porque não operamos em períodos de alta temporada.
- Se o desempenho do modelo estiver abaixo de um limite, treine novamente o modelo automaticamente. Usamos uma estratégia simples para escolher os dados para retreinar, um período de janela dos últimos dois anos de dados para retreinar, ele retreina na mesma configuração do modelo, mas faz o hiperajuste novamente. O treinamento é novamente rastreado para MLFlow. Depois, se o desempenho do modelo estiver acima do limite, implante-o na Vertex AI.
A estratégia escolhida foi não treinar novamente se o modelo não fosse quebrado ou o desempenho variasse. Essa abordagem pode não ser a ideal, pois o modelo poderia ser melhor se fosse treinado novamente com novos dados, mas entendemos que era suficiente e não queríamos gastar recursos quando não fossem necessários.
Conforme mencionamos na solução, concluímos que sempre haverá algum grau de desvio de dados comparando os dados de produção e de treinamento. Poderíamos monitorá-lo também, mas atualmente, com a diminuição do COVID-19 estamos aumentando os destinos operados e muita coisa pode mudar no comportamento, por isso preferimos manter a simplicidade e apenas avaliar o desempenho do modelo, retreinando-o mensalmente quando necessário . Em trabalhos futuros adicionaremos um fluxo de trabalho de monitoramento de desvio de dados.
Também é importante mencionar que temos versionamento de modelos tanto no Vertex AI quanto no MLFlow Model Registry e versionamento de código no Github, assim mantemos o controle do que está acontecendo e podemos reverter se algo der errado.
No geral, temos sempre um modelo atualizado na produção e todo o processo é transparente para os stakeholders. Recebemos notificações por e-mail sempre que o fluxo de trabalho é executado e podemos continuar monitorando a latência e os erros na interface do Vertex AI. Além disso, fizemos uma documentação completa no Github e coda explicando todos os processos e decisões tomadas no projeto.
Conclusão
Desenvolvemos um modelo de aprendizado de máquina ponta a ponta que pode prever a probabilidade de um cliente aceitar uma opção de voo. Isso ajudou a escalar nossas operações, reduzindo riscos e custos e também aumentando a satisfação dos clientes.
Além disso, o modelo é constantemente atualizado com novos dados e reagindo às mudanças no comportamento dos clientes. Isso foi possível integrando ferramentas de código aberto, como MLFlow, BentoML e Flyte, com a pilha e ferramentas do Google, como VertexAI e Bigquery.
Nossa equipe de aprendizado de máquina também está melhorando continuamente nossos processos e pilha para agregar valor ao Hurb e, como por produto, ao nosso cliente.
Espero que você tenha gostado deste artigo! Se você quiser fazer parte da nossa equipe de aprendizado de máquina, encontre nossas vagas de emprego aqui . Além disso, você pode conferir mais sobre nosso trabalho no Hurb em nossa página do Medium .





