

Em 2024, o Google Research impulsionou avanços em pesquisas e os traduziu em impacto em todas as escalas — computacional, humana, social e global — em um esforço para abordar alguns dos maiores desafios e questões científicas de nossos tempos.
Ao refletir sobre o ano passado no Google Research, o que se destaca é o ritmo impressionante da inovação. Nunca antes fomos capazes de avançar tecnologias como IA, ML fundamental, algoritmos e computação quântica com o ritmo, propósito e parcerias dos quais nos beneficiamos hoje, permitindo-nos impulsionar a inovação e abordar alguns dos maiores desafios e questões científicas de nossos tempos. Estamos construindo sobre a rápida ascensão do aprendizado de máquina, impulsionando avanços em pesquisa e traduzindo-os em impacto em todas as escalas — computacional, humana, social e global. Tenho orgulho de compartilhar alguns destaques do que foi um ano extraordinário.
Computação clássica e quântica: a base da inovação
Os avanços que fizemos este ano na computação clássica e quântica formam a base para uma amplitude de inovações. Mais recentemente, demos passos gigantescos no campo da computação quântica, abrindo caminho para um computador quântico útil em larga escala. Willow , nosso novo chip quântico, oferece desempenho de última geração: ele pode executar uma computação de referência em menos de cinco minutos, em comparação com os 10 septilhões (10 25 ) anos que um dos supercomputadores mais rápidos da atualidade levaria. Criticamente, nossos resultados publicados na Nature demonstraram que o Willow reduz erros exponencialmente à medida que aumentamos e usamos mais qubits, as unidades de informação na computação quântica. Isso resolve um dos maiores desafios de engenharia na computação quântica até o momento, ou seja, que os qubits são afetados por interações com o ambiente, o que torna os computadores quânticos propensos a erros e limita o número de qubits que eles podem manipular. Avaliamos o desempenho do Willow usando amostragem de circuito aleatório , um método que relatamos anteriormente para avaliar o desempenho de computadores quânticos. Para tornar a computação quântica mais confiável e útil, especialmente em escala, também estamos trabalhando para identificar e corrigir erros. Apresentamos o AlphaQubit , um decodificador baseado em rede neural desenvolvido em colaboração com o Google DeepMind e publicado na Nature , que identifica erros com precisão de ponta. Essas inovações nos aproximam de uma realidade em que a computação quântica pode responder a desafios científicos não resolvidos anteriormente, desde o projeto de reatores de fusão nuclear até a aceleração da descoberta de medicamentos .

Qubits lógicos em processadores progressivamente melhores, com uma melhoria de 2x em qubits físicos e aumentando o tamanho a cada passo . Quadrados vermelhos e azuis correspondem a verificações de paridade indicando erros próximos. Os processadores podem executar de forma confiável aproximadamente 50, 10 3 , 10 6 e 10 12 ciclos, respectivamente.
Fizemos um grande progresso nas fundações de ML, com um trabalho extensivo em algoritmos, eficiência, dados e privacidade. Melhoramos a eficiência de ML por meio de técnicas pioneiras que reduzem os tempos de inferência de LLMs, que foram implementadas em todos os produtos do Google e adotadas em todo o setor. Nossa pesquisa sobre cascatas apresenta um método para alavancar modelos menores para saídas “fáceis”, enquanto nosso novo algoritmo de decodificação especulativa calcula vários tokens em paralelo, acelerando a geração de saídas em ~2x–3x sem afetar a qualidade. Como resultado, os LLMs que alimentam produtos de conversação podem gerar respostas significativamente mais rápido. Isso equivale a uma experiência do usuário muito melhorada e torna a IA mais eficiente em termos de computação e energia. Estamos desenvolvendo esse trabalho com refinamento de rascunho e verificação de bloco . Também examinamos novas maneiras de melhorar as capacidades de raciocínio dos LLMs por meio de tokens de pausa — o aumento do poder de raciocínio pode tornar os modelos menores mais poderosos, resultando em ganhos significativos de eficiência. Exploramos a eficiência algorítmica dos transformadores e projetamos PolySketchFormer , HyperAttention e Selective Attention , três novos mecanismos de atenção, para abordar desafios computacionais e gargalos na implantação de modelos de linguagem e melhorar a qualidade do modelo.
Nossas equipes fizeram progresso adicional considerável, incluindo pesquisa sobre algoritmos de diferimento de princípios com vários especialistas e um algoritmo de diferimento de configuração geral de dois estágios . Nosso algoritmo de aprendizado de imitação RL para otimização do compilador levou a economias significativas e redução do tamanho de arquivos binários; nossa pesquisa sobre aprendizado de reforço multiobjetivo a partir de feedback humano, a estrutura da Conditional Language Policy , forneceu uma solução baseada em princípios com uma troca fundamental de qualidade-factualidade e economias significativas de computação; e o trabalho em aprendizado em contexto forneceu um mecanismo para aprendizado com eficiência de amostra para tarefas de recuperação esparsas.
Dados são outro bloco de construção crítico para ML. Para dar suporte à pesquisa de ML em todo o ecossistema, lançamos e contribuímos para vários conjuntos de dados. Croissant , por exemplo, é um formato de metadados projetado para as necessidades específicas de dados de ML, que projetamos em colaboração com a indústria e a academia. Desenvolvemos amostragem de sensibilidade , uma técnica de amostragem de dados para modelos de base, e provamos que esta é uma estratégia de amostragem de dados ideal para problemas clássicos de agrupamento, como k -means. Avançamos em nossa pesquisa em algoritmos de agrupamento escaláveis e disponibilizamos uma biblioteca de agrupamento de gráficos paralelos de código aberto, fornecendo resultados de última geração em gráficos de bilhões de arestas em uma única máquina. A rápida proliferação de modelos de aprendizado de máquina específicos de domínio destaca um desafio fundamental: embora esses modelos se destaquem em seus respectivos domínios, seu desempenho geralmente varia significativamente em diversos aplicativos. Para abordar isso, nossa pesquisa desenvolveu um algoritmo baseado em princípios , enquadrando o problema como uma tarefa de adaptação de domínio de múltiplas fontes.
O Google Research está profundamente comprometido com a pesquisa de privacidade e fez contribuições significativas para o campo. Nosso trabalho em treinamento de modelos diferencialmente privados destaca a importância da análise rigorosa e implementação de algoritmos de ML que preservam a privacidade para garantir proteção robusta dos dados do usuário. Complementamos essas análises com algoritmos mais eficientes para treinamento e novos métodos para auditar implementações, que disponibilizamos de código aberto para a comunidade. Em nossa pesquisa sobre aprendizado de dados agregados, introduzimos uma nova abordagem para construir conjuntos de dados de agregação e exploramos vários aspectos algorítmicos do aprendizado de modelos de dados agregados, o que atingiu taxas otimistas de complexidade de amostra neste cenário. Também projetamos novos métodos para gerar dados sintéticos diferencialmente privados — dados que são artificiais e oferecem forte proteção de privacidade, ao mesmo tempo em que ainda têm as características necessárias para treinar modelos preditivos.
À medida que expandimos os limites do que pode ser alcançado na otimização computacional, há implicações significativas para a economia global. Considere a programação linear (LP), um método fundamental da ciência da computação que informa a tomada de decisões orientada por dados e tem muitas aplicações em campos como manufatura e transporte. Introduzimos o PDLP , que requer menos memória, é mais compatível com técnicas computacionais modernas e amplia significativamente os recursos de resolução de LP. Ele recebeu o prestigioso prêmio Beale — Orchard-Hays e agora está disponível como parte do OR-Tools de código aberto do Google . Anunciamos nossa Shipping Network Design API , um ótimo exemplo de caso de uso de PDLP, para otimizar o transporte de cargas . Isso permite soluções mais ambientais e econômicas para os desafios da cadeia de suprimentos, com o potencial para as redes de transporte entregarem 13% mais contêineres com 15% menos embarcações. Introduzimos o Times-FM também para previsões de séries temporais mais precisas, um tipo de previsão amplamente utilizado em domínios como varejo, manufatura e finanças. Este modelo de base somente decodificador foi pré-treinado em 100 bilhões de pontos de tempo do mundo real, usando amplamente dados do Google Trends e visualizações de páginas da Wikipédia, e superou até mesmo modelos poderosos de aprendizado profundo que foram treinados nas séries temporais de destino.

Nós projetamos o PDLP como um pacote de software que pode resolver problemas de programação linear de forma eficiente. O algoritmo central do PDLP é baseado no PDHG reiniciado, que nós aprimoramos significativamente. Aqui mostramos os comportamentos de convergência do PDHG e do PDHG reiniciado, onde o eixo x é a solução atual do LP, e o eixo y é a solução atual do LP dual.
Aplicando nossa pesquisa ao reino popular dos jogos, nosso modelo GameNGen mostrou que um videogame complexo pode ser simulado em tempo real e em alta qualidade com um modelo neural. E voltando-se para a publicidade, fizemos uma parceria com a equipe de anúncios para lançar anúncios em AI Overviews on Search para expor negócios, produtos e serviços mais relevantes dentro da experiência de IA generativa do Google, enquanto também exploramos novos mecanismos e design de leilão conforme a experiência evolui. Também publicamos uma pesquisa sobre nosso trabalho em leilões de anúncios com lances automáticos.
Abordagens avançadas tornam os modelos de linguagem mais capazes e confiáveis
A IA generativa já está transformando a forma como acessamos informações, e a confiabilidade dessas informações é uma prioridade máxima para os usuários e para a sociedade como um todo. Este ano, construímos nosso longo legado de trabalho fundamental para avançar a qualidade do conteúdo gerado por IA. Fomos pioneiros em abordagens de última geração para fundamentar grandes modelos de linguagem e reduzir alucinações, por exemplo, treinando modelos para confiar em documentos de origem para resumo e combinando dados estruturados, como gráficos, com LLMs para melhorar a qualidade da geração aumentada de recuperação . Nossos modelos aprimorados estão alimentando os novos recursos “Fontes relacionadas” e “Verificação dupla” no Gemini , que permitem que os usuários se aprofundem nos tópicos e entendam melhor a resposta às suas consultas.


Os usuários podem clicar no ícone no final de um parágrafo para exibir links para conteúdo relacionado a prompts de busca de fatos no Gemini.
Benchmarks são importantes para avaliar a consistência factual — e nós os usamos há anos neste espaço. Em colaboração com o Google DeepMind e o Kaggle, recentemente compartilhamos o FACTS Grounding Leaderboard para fornecer uma plataforma para benchmarking mais abrangente. O recém-lançado Gemini 2.0 alcançou uma pontuação de correção de 83,6% no FACTS leaderboard e uma taxa de alucinação <2% no Vectara leaderboard.
À medida que a IA generativa se torna multimodal, os usuários também esperam que as imagens e vídeos gerados retratem com precisão cenários do mundo real. Introduzimos Time-Aligned Captions , uma estrutura que pode usar descrições de texto para gerar vídeos multicenas que são visualmente consistentes de uma cena para a outra. Com nosso método de difusão de vídeo sequencial contrastante , é possível até que cenas que não são adjacentes umas às outras sejam visualmente consistentes. Isso é útil para criar vídeos com padrões não lineares, como instruções de receitas ou projetos do tipo “faça você mesmo”. Também treinamos um modelo unificado para prever feedback humano rico , por meio de mapas de calor de atenção, por exemplo, para melhorar a geração de imagens, e projetamos um método pelo qual os modelos de linguagem de visão podem articular desalinhamentos entre um prompt de texto e a imagem gerada. Isso pode aprofundar nossa compreensão das causas do desalinhamento dentro dos pares texto-imagem e ajudar a melhorar os modelos generativos.


Exemplos de heatmaps de implausibilidade. No heatmap Groundtruth, a cor representa quantos anotadores marcam a região como implausível. Vermelho/amarelo/azul significa que 3/2/1 anotadores marcam as regiões, respectivamente. Na predição, a cor representa a intensidade do sinal (probabilidade). Quanto mais quente uma região for, mais provável é que o modelo a preveja como implausível.
Tornar os modelos de linguagem mais confiáveis é um esforço de longo prazo: a natureza cada vez mais complexa dos modelos de ML exige abordagens cada vez mais avançadas para garantir sua precisão e utilidade. É por isso que projetamos uma nova estrutura para investigar representações ocultas em LLMs com LLMs , por meio da qual o modelo fornece explicações em linguagem natural sobre como ele representa o que aprendeu. No futuro, isso nos permitirá entender melhor como os modelos de linguagem funcionam, corrigir erros de raciocínio e corrigir alucinações. Também exploramos o raciocínio dentro de redes neurais baseadas em transformadores. Introduzimos uma hierarquia representacional que categoriza problemas de gráfico por complexidade, caracterizamos o potencial dos transformadores para superar redes neurais de gráfico especializadas e exploramos como melhor representar gráficos de conexões dentro de uma rede como texto. Esses estudos lançam luz sobre as capacidades de raciocínio dos transformadores e permitirão que os LLMs respondam com mais precisão a perguntas sobre informações conectadas. Além da precisão, reconhecer a incerteza no caso de múltiplas saídas possíveis pode ajudar a construir confiança da mesma forma que uma pessoa pode dizer: “Não tenho certeza, mas acho…” Nossa pesquisa avalia a capacidade dos LLMs modernos de transmitir sua própria incerteza e demonstra a necessidade de melhor alinhamento.
À medida que nos esforçamos para atender bilhões de pessoas ao redor do mundo e tornar a IA acessível para todos os usuários, nossos modelos de IA devem adotar diferentes idiomas, culturas e sistemas de valores. Criamos conjuntos de dados multilíngues que capturam conhecimento rico e diferenciado sobre vários aspectos das culturas globais, como termos ofensivos , estereótipos socioculturais e artefatos . Colaboramos com linguistas e desenvolvemos técnicas de preservação da privacidade para identificar palavras que não são oficialmente parte da linguagem — novas tendências como “Wordle” ou nomes de locais, por exemplo — para melhorar os recursos de autocorreção e previsão de palavras no Gboard . Também fomos pioneiros em novos métodos para selecionar conhecimento culturalmente fundamentado de diversas comunidades e desenvolvemos abordagens para acelerar a criação de conjuntos de dados em escala global e impulsionar a próxima geração de modelos e agentes de IA socialmente inteligentes.
Uma mudança em direção à educação e à assistência médica personalizadas
Em nenhum lugar informações precisas são mais importantes do que nos domínios da educação e da saúde. Nesses campos, os avanços em IA estão impulsionando uma mudança notável em direção a uma abordagem mais personalizada. No Google I/O em maio, apresentamos o LearnLM , uma família de modelos ajustados para aprendizado que foram desenvolvidos em colaboração com o Google DeepMind e parceiros de produtos. O LearnLM é baseado em pesquisa educacional e torna o aprendizado mais envolvente e pessoal ao se adaptar dinamicamente às necessidades e objetivos do aluno. Integrado em nossos produtos, isso permite que os alunos, por exemplo, “levantem a mão” enquanto assistem a vídeos acadêmicos no YouTube para fazer perguntas esclarecedoras ou peçam ao Gemini para ” me questionar ” sobre um tópico. Estamos trabalhando em estreita colaboração com educadores para levar esses recursos para a sala de aula de uma forma segura e útil que capacite os professores. Para começar, pilotamos o Gemini no Google Classroom , que oferece aos professores recursos de planejamento de aulas adaptados ao nível de ensino-alvo.
Da mesma forma, nossos modelos ajustados para o domínio médico, MedLM e Search for Healthcare na Google Cloud Platform, estão ajudando a democratizar o acesso a cuidados personalizados de alta qualidade com IA generativa . Os modelos combinam as habilidades multimodais e de raciocínio do Gemini com treinamento em dados médicos desidentificados. Demonstramos pela primeira vez como grandes modelos multimodais como esses podem interpretar exames 3D ou gerar relatórios de radiologia de última geração. Também introduzimos um LLM que visa analisar dados pessoais e fisiológicos de dispositivos vestíveis e sensores. Este LLM de Saúde Pessoal será capaz de fornecer aos usuários do Fitbit e do Pixel insights personalizados para perguntas como “Como posso me sentir mais energético durante o dia?” Além disso, estamos imaginando maneiras pelas quais os sistemas de IA podem ser parceiros de conversação úteis para médicos e pacientes. Em parceria com o Google DeepMind, desenvolvemos o Articulate Medical Intelligence Explorer (AMIE), um sistema experimental otimizado para raciocínio diagnóstico e conversas, que pode fazer perguntas inteligentes com base no histórico clínico de uma pessoa para ajudar a derivar um diagnóstico, e exploramos seu potencial em domínios médicos subespecializados , como câncer de mama, onde o diagnóstico oportuno é crucial.

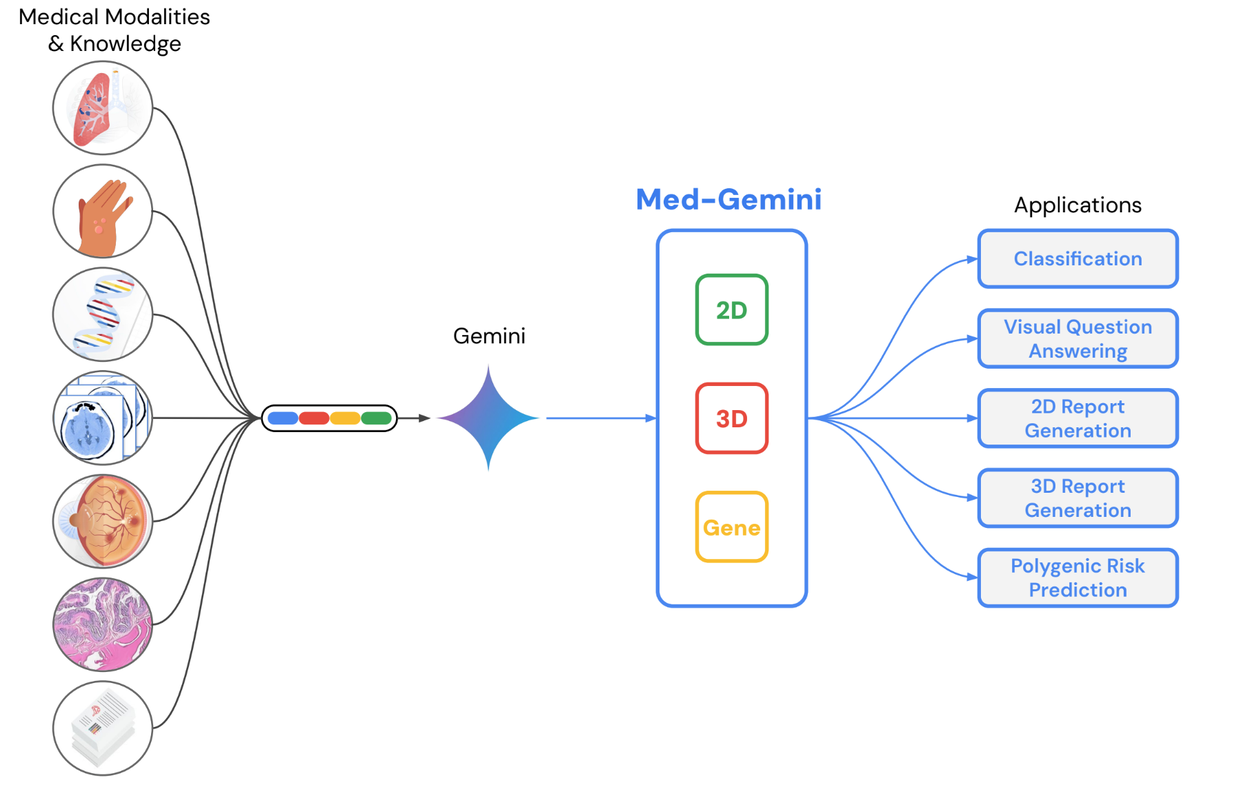
Treinado em uma variedade de imagens médicas 2D convencionais (raios-X de tórax, cortes de TC, lâminas de patologia, etc.) usando dados médicos desidentificados com rótulos de texto livre, o Med-Gemini-2D é capaz de executar uma série de tarefas, como classificação, resposta visual a perguntas e geração de texto.
Também avançamos em nossa pesquisa em genômica para entender melhor as predisposições genéticas dos indivíduos a doenças e diagnosticar doenças raras. Apresentamos o REGLE , um modelo de aprendizado profundo não supervisionado que ajuda os pesquisadores a usar dados clínicos de alta dimensão em escala para descobrir associações com variantes genéticas. Também disponibilizamos novos modelos DeepVariant de código aberto como parte de uma colaboração em Personalized Pangenome References , que pode reduzir erros em 30% ao analisar genomas de diversas ancestralidades.
À medida que percebemos a incrível oportunidade e os benefícios da assistência médica personalizada por meio do desenvolvimento de ferramentas baseadas em ML, é imperativo fazê-lo de forma responsável. Para garantir a equidade em saúde, introduzimos a estrutura HEAL (Health Equity Assessment of machine Learning performance). Esta é uma estrutura de avaliação para avaliar quantitativamente se uma ferramenta de saúde baseada em ML tem um desempenho equitativo, a fim de informar o desenvolvimento do modelo e a avaliação do mundo real. O objetivo é ajudar a reduzir as disparidades nos resultados de saúde para pessoas de diferentes sexos, etnias e origens socioeconômicas.
Soluções dimensionadas para desafios científicos e globais
À medida que as técnicas computacionais e os modelos de ML se tornam progressivamente mais avançados e precisos, nossos pesquisadores conseguem enfrentar desafios em grande escala, desde a precisão do GPS até a questão urgente das mudanças climáticas.
A capacidade de processar dados em uma escala sem precedentes está nos ajudando a desvendar mistérios científicos — e existe um mistério maior do que o cérebro humano, sem dúvida a máquina computacionalmente mais complexa que existe? Marcamos 10 anos de pesquisa em conectômica no Google com uma publicação na Science lançada em parceria com Harvard que apresentou a maior reconstrução assistida por IA de tecido cerebral humano no nível sináptico. Isso pode ajudar a melhorar nossa compreensão de como os cérebros funcionam.

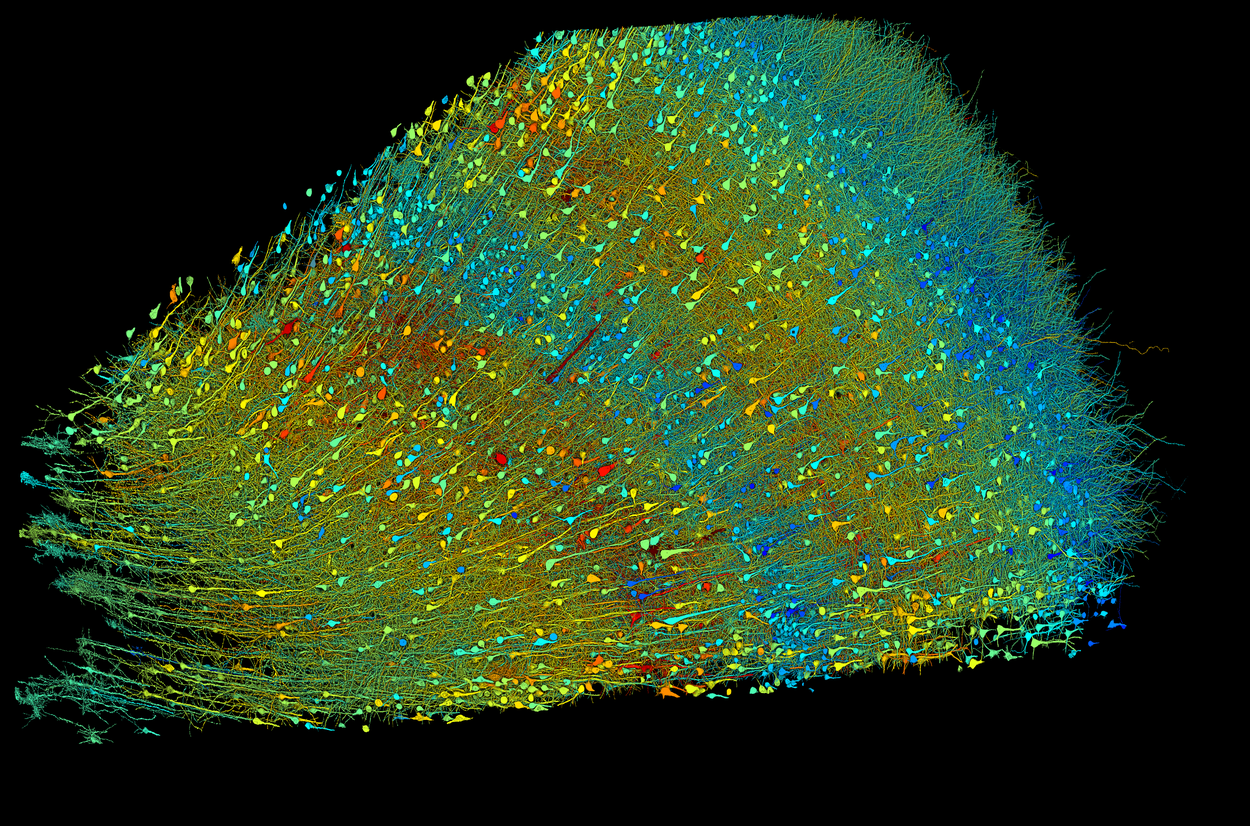
Pesquisadores construíram uma imagem 3D de quase todos os neurônios e suas conexões dentro de um pequeno pedaço de tecido cerebral humano. Esta imagem mostra neurônios excitatórios , que variam de 15 a 30 micrômetros de diâmetro e são sombreados de acordo com o tamanho dos corpos celulares dos neurônios (núcleo central). A amostra tem aproximadamente 3 mm de largura. Crédito: Google Research e Lichtman Lab (Universidade de Harvard). Renderizações por D. Berger (Universidade de Harvard).
Nosso uso de medições agregadas de sensores de milhões de telefones Android para mapear a ionosfera , uma região da atmosfera superior da Terra que é ionizada pela radiação solar, é outro exemplo em que os avanços na computação têm impacto de longo alcance. Eventos geomagnéticos na ionosfera, como a radiação de tempestades solares, podem interromper a infraestrutura crítica, ou seja, comunicações por satélite e sistemas de navegação. O mapeamento, publicado na Nature , nos permitirá melhorar a precisão da localização do GPS em vários metros e fornece aos cientistas um nível de detalhes sem precedentes sobre a ionosfera em regiões que têm poucas estações de monitoramento. Também introduzimos o NeuralGCM na Nature , um modelo que pode simular com precisão a atmosfera da Terra mais rapidamente do que os modelos de física de última geração. Ele foi desenvolvido em parceria com o Centro Europeu de Previsões Meteorológicas de Médio Prazo e combina modelagem tradicional baseada em física com ML. Disponibilizamos o código-fonte no GitHub na esperança de que outros pesquisadores possam melhorar a funcionalidade do modelo e, no futuro, ajudará os cientistas a entender e prever como nosso clima está mudando ao longo do tempo. SEEDS é outra inovação que abre novas oportunidades para a ciência do clima e do tempo: é um modelo de IA generativo que pode gerar previsões meteorológicas em larga escala e com eficiência, por uma fração do custo dos modelos tradicionais de previsão baseados em física.

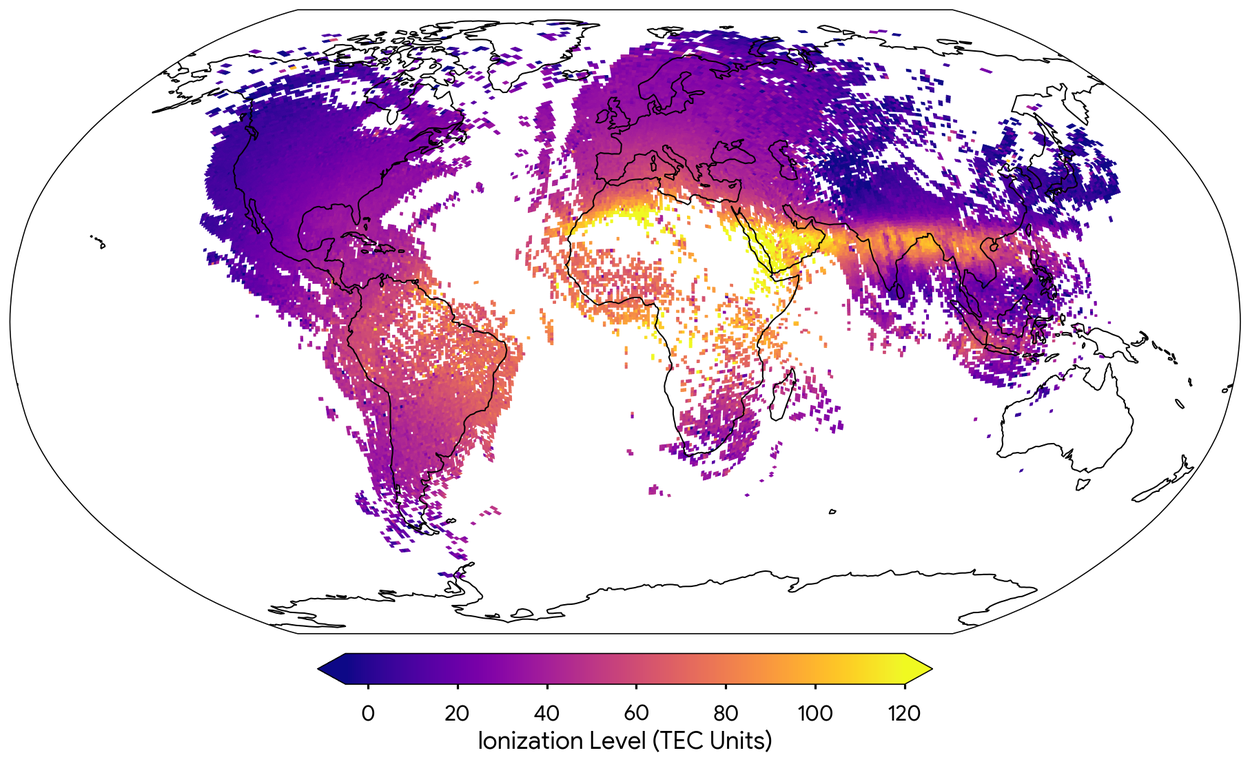
Um mapa mundial de ionização atmosférica feito a partir de dez minutos de medições por telefone em 12 de outubro de 2023 às 14h UTC. O gradiente de cores mostra a quantidade de ionização, de roxo (baixa densidade de íons) a amarelo (alta densidade de íons). Os dados foram capturados em locais onde tínhamos medições suficientes: o lado diurno da Terra e áreas com maior densidade populacional.

O NeuralGCM simulou padrões de umidade específica durante um período de 14 dias, de 26 de dezembro de 2019 a 8 de janeiro de 2020. Valores mais altos de umidade específica são mostrados em cores mais claras.
Informações confiáveis e oportunas são essenciais para capacitar comunidades e governos a tomar medidas para minimizar os danos causados por desastres naturais, como inundações e incêndios florestais, fenômenos que estão se tornando mais frequentes e destrutivos à medida que as temperaturas globais aumentam. Desenvolvemos modelos de hidrologia baseados em IA , publicados na Nature no início deste ano, capazes de prever inundações fluviais ao redor do mundo, mesmo em regiões com escassez de dados, como a África. Melhoramos ainda mais o modelo para que agora ele forneça cobertura para mais de 700 milhões de pessoas que vivem em áreas de risco em 100 países, com um prazo de 7 dias antes que as inundações ocorram, superando os modelos de última geração. Todas as informações estão disponíveis publicamente no Flood Hub , e oferecemos aos pesquisadores e usuários especialistas em domínios de gerenciamento de desastres a oportunidade de se inscrever para acesso à API para mais dados. Para ajudar as pessoas a se manterem seguras quando ocorrem incêndios florestais, expandimos nosso rastreador de limites de incêndios florestais para cobrir 22 países. Ele usa IA e imagens de satélite e disponibiliza informações críticas na Pesquisa, Mapas e por meio de notificações push baseadas em localização. Lançamos nosso conjunto de dados Firebench para avançar a pesquisa neste campo, disponibilizando-o na Google Cloud Platform . Este conjunto de dados sintéticos de alta resolução permite que pesquisadores simulem e investiguem o comportamento de propagação de incêndios florestais e oferece suporte ao desenvolvimento de soluções de ML capturando as dependências entre variáveis relevantes. Também fizemos uma parceria com a Moore Foundation e a Muon Space para desenvolver o FireSat , uma constelação de satélites especialmente construída com o objetivo de detectar incêndios florestais em qualquer lugar do mundo em vinte minutos e permitir que cientistas e especialistas em ML estudem a propagação do fogo.


Estamos desenvolvendo o FireSat, a primeira constelação de satélites focada na detecção precoce de incêndios florestais em imagens de alta resolução.
Apoiando grande parte da nossa pesquisa climática e nos permitindo abordar um espectro de outros desafios globais urgentes, está o desenvolvimento de modelos fundamentais. Por exemplo, introduzimos um modelo de base de dinâmica populacional e um conjunto de dados que podem ser facilmente adaptados para resolver uma ampla gama de problemas geoespaciais abrangendo tarefas de saúde pública, socioeconômicas e ambientais. No centro do modelo está uma rede neural gráfica . Ela incorpora dados agregados centrados no ser humano, dados ambientais e características locais para permitir uma compreensão mais matizada da dinâmica populacional ao redor do mundo.
Progresso responsável através de parcerias
No Google Research, valorizamos muito a colaboração e as parcerias e nos envolvemos com o ecossistema de pesquisa mais amplo por meio de publicações , lançamento de conjuntos de dados e modelos de código aberto, parcerias com universidades e organizações ao redor do mundo e participação em conferências de pesquisa, como a recente NeurIPS .
Isso anda de mãos dadas com ter uma equipe global que colabora com parceiros no local e realiza pesquisas que abordam as necessidades de suas comunidades. Nossas equipes na África, por exemplo, estão liderando nossa pesquisa sobre segurança alimentar em parceria com o Programa Mundial de Alimentos e com financiamento do Google.org , e fazemos parceria com a ONU e a GiveDirectly para tornar nossa tecnologia de previsão de enchentes e resposta a desastres úteis para comunidades locais. Nossa equipe de saúde desenvolveu uma ferramenta de IA para triagem de pacientes diabéticos para ajudar a prevenir a cegueira junto com parceiros de pesquisa na Índia e na Tailândia, e licenciou o modelo para provedores de saúde com o objetivo de fornecer 6 milhões de exames nos próximos 10 anos, sem nenhum custo para os pacientes. Esta equipe também está trabalhando em todos os continentes para avaliar o impacto de um assistente de IA para triagem de câncer de pulmão em fluxos de trabalho clínicos no Japão e nos EUA.
Por meio da colaboração, somos capazes de promover pesquisas de ponta e aplicar nossas soluções de forma responsável no mundo real, em linha com nossos principais princípios de IA responsável para garantir que nossa pesquisa mantenha os mais altos padrões de excelência científica e seja socialmente benéfica.
Quero aproveitar esta oportunidade para agradecer a todos no Google Research e nossos muitos parceiros pelo progresso e impacto notáveis neste ano — o acima é apenas um instantâneo do que alcançamos juntos. À medida que continuamos a avançar tecnologias como IA, Quantum, Algoritmos e ML fundamental, estou otimista sobre o impacto positivo que podemos ter em bilhões de pessoas e no mundo.