Em ‘Notícias’, do Blog do Hurb, você encontra as últimas novidades e tendências do setor de turismo e lazer. Fique por dentro de atualizações importantes, mudanças no mercado, eventos, e tudo o que movimenta o universo das viagens e experiências ao redor do mundo.
Se você é um fã de carteirinha da Disney, prepare-se para um desafio emocionante! Celebrando os 100 anos do The Walt Disney Company, criamos um quiz especial para testar seus conhecimentos sobre os personagens que encantaram gerações. Descubra quais são os personagens a seguir. Bora!?
Você já pensou em um mundo onde a imaginação corre solta, os sonhos se tornam realidade e a magia está sempre à espreita? Durante a sua infância, provavelmente já se deixou levar pelo encanto dos personagens icônicos da The Walt Disney Company. Este mês de setembro é um marco: Disney 100 anos. Para comemorar um século de pura magia, aventuras e memórias, vamos contar a história de uma das companhias mais famosas do mundo.
Há 100 anos, Walt Disney e Roy O. Disney iniciaram uma jornada mágica que mudaria o mundo do entretenimento para sempre. Em 1923, eles fundaram a Disney Brothers Cartoon Studio, que mais tarde se tornaria a The Walt Disney Company. Em 1928, a estreia do Mickey Mouse em “Steamboat Willie” encantou o mundo e inaugurou a era de ouro da animação. Outros personagens amados, como Minnie, Donald, Pateta e Pluto, rapidamente se juntaram à festa.
A era de ouro da animação: 1950-1980
Os anos dourados da Disney viram a criação de clássicos inesquecíveis como “A Branca de Neve e os Sete Anões“, “Cinderela” e “A Bela e a Fera“. Esses filmes conquistaram o coração de crianças e adultos, provando que a magia Disney era eterna. Os parques temáticos da Disney também começaram a se espalhar pelo mundo, permitindo que as pessoas mergulhassem ainda mais fundo nesse universo encantado.
A diversificação e expansão: 1980-2000
Nos anos 80 e 90, a companhia expandiu seu império para a televisão e adquiriu marcas como a Pixar, Marvel e Lucasfilm, dando vida a novos heróis como Buzz Lightyear, Homem de Ferro e Luke Skywalker. Além disso, personagens contemporâneos como Simba e Ariel se juntaram às fileiras dos amados ícones Disney. Os parques temáticos se tornaram destinos de sonho para pessoas de todo o mundo.
O legado contínuo: 2000-2023
À medida que entramos no século XXI, a companhia continua a encantar com sucessos como Frozen, Moana e a expansão do universo Marvel e Star Wars. A magia não tem idade, e pessoas de todas as gerações continuam a se apaixonar por personagens atemporais como Mickey e Minnie. Os parques temáticos inovam constantemente para proporcionar experiências únicas aos visitantes.
À medida que celebramos os 100 anos da companhia, é emocionante pensar no que o futuro reserva. Novas histórias, personagens e aventuras estão a caminho, mantendo viva a tradição de encantar e inspirar gerações. A magia transcende o tempo e o espaço, e com certeza continuará a tocar os corações de todos que buscam um pouco de magia em suas vidas.
Em 100 anos de histórias incríveis, personagens inesquecíveis e momentos mágicos, a The Walt Disney Company deixou uma marca no coração de todos nós. Que essa jornada mágica continue a nos encantar e inspirar por muitos e muitos anos. Que a magia nunca acabe!
Alô, viajantes de plantão! Para comemorar o Dia do Cliente, que é celebrado nesta sexta-feira (15), lançamos uma promoção exclusiva com pacotes de viagens imperdíveis para três destinos incríveis: Santiago, Arraial D’Ajuda e Curitiba. Mas atenção: essas ofertas são limitadas e serão divulgadas em 3 lotes, então corra porque elas vão desaparecer em um piscar de olhos!
Santiago – o charme dos Andes
Santiago, a capital do Chile, é um verdadeiro paraíso para os amantes da natureza e da cultura. A cidade está rodeada pelas montanhas dos Andes, que oferecem oportunidades incríveis para esquiar no inverno e fazer trilhas no verão. Você também não pode perder uma visita ao famoso Mercado Central para experimentar pratos típicos chilenos, como o ceviche. Confira as informações da nossa promoção especial de Dia do Cliente para Santiago:
Pacote de 4 diárias
Inclui passagens aéreas de ida e volta
Acomodação em hotel
A partir de R$ 1.168
Parcelas: 12x (cartão de crédito) e 8x (boleto)
Arraial D’Ajuda – paraíso brasileiro
Se você está em busca de praias paradisíacas e um clima tropical, Arraial D’Ajuda, na Bahia, é o seu destino ideal. Com suas praias de areia branca e águas cristalinas, este é o lugar perfeito para relaxar e aproveitar o sol. Não deixe de visitar a Rua Mucugê, cheia de bares e restaurantes charmosos. Confira as informações da nossa promoção especial de Dia do Cliente para Arraial D’Ajuda:
Pacote de 4 diárias
Inclui passagens aéreas de ida e volta
Acomodação em hotel
Café da manhã
A partir de R$ 1.081
Parcelas: 12x (cartão de crédito) e 8x (boleto)
Curitiba – charme e cultura no sul do Brasil
Curitiba, no sul do Brasil, é uma cidade encantadora conhecida por sua arquitetura única e cultura vibrante. Não perca uma visita ao Jardim Botânico, um dos cartões-postais da cidade, e ao Museu Oscar Niemeyer, com sua arquitetura moderna. Confira as informações da nossa promoção especial de Dia do Cliente para Curitiba:
Pacote de 4 diárias
Inclui passagens aéreas de ida e volta
Acomodação em hotel
Café da manhã
A partir de R$ 677
Parcelas: 12x (cartão de crédito) e 8x (boleto)
Esta é a sua chance de celebrar o Dia do Cliente com uma viagem inesquecível a preços incríveis! Lembre-se de que as ofertas são limitadas, então não espere muito tempo para reservar o seu pacote de viagem dos sonhos. Vamos tornar o seu Dia do Cliente ainda mais especial!
Na América Latina, existe um lugar onde você não encontrará um Big Mac no menu: a Bolívia. O país tomou a decisão de manter a marca McDonald’s fora de suas fronteiras em 2002, após apenas sete anos de operação em La Paz. E a história por trás dessa peculiaridade revela muito sobre a cultura e os hábitos alimentares que respeitam as tradições locais.
Os bolivianos têm uma tradição culinária rica, com pratos tradicionais como salteñas, anticuchos e tucumanas, que são amplamente apreciados. São refeições caseiras, feitas com ingredientes locais frescos e enfatizando a tradição.Essa foi a grande dificuldade do McDonald’s por lá. Os bolivianos preferem alimentos frescos e nutritivos, e a ideia de fast food processado não se alinhou com suas preferências alimentares. Além disso, os preços relativamente elevados dos produtos McDonald’s não eram acessíveis para muitos bolivianos.
O produto mais barato do McDonald’s custava cerca de $ 25 pesos bolivianos, aproximadamente US $ 3, enquanto que em uma empresa local um almoço completo custava cerca de $ 7 pesos, menos de um dólar. Outra preocupação foi a saúde. A Bolívia tem uma taxa de obesidade relativamente baixa em comparação com muitos países ocidentais, e a população estava preocupada que a presença do McDonald’s pudesse mudar esse cenário tão positivo..
Em última análise, a decisão de não ter McDonald’s na Bolívia reflete a diversidade cultural e culinária do país. Os bolivianos optaram por manter suas tradições alimentares e valorizar ingredientes locais e frescos. Isso torna a Bolívia um lugar único na América Latina, onde a comida caseira e tradicional ainda domina a cena gastronômica, e onde você não encontrará um Big Mac à vista. Se você visitar a Bolívia, prepare-se para saborear a autêntica culinária local, uma experiência única em sua categoria.
Vivemos em um mundo com uma explosão de informações. Há milhões de roupas, músicas, filmes, receitas, carros, casas, qual você deve escolher? A pesquisa semântica pode encontrar a certa para qualquer gosto e desejo!Neste artigo, vou apresentar o que é pesquisa semântica, o que pode ser construído com ela e como construí-la. Por exemplo, por que as pessoas procuram roupas?
Eles gostam da marca, da cor, da forma ou do preço. Todos esses aspectos podem ser usados para encontrar o melhor.A cor e a forma podem ser encontradas usando a imagem, e o preço e a marca são encontrados nas tendências.Imagens e tendências podem ser representadas como pequenos vetores chamados incorporações.
As incorporações são o núcleo da pesquisasemântica: uma vez que os itens são codificados como vetores, é rápido e eficiente procurar os melhores itens.Vou explicar como a pesquisa semântica funciona: codificar itens como incorporações, indexá-los e usar esses índices para pesquisa rápida, a fim de construir sistemas semânticos.
1. Motivação: por que pesquisar, por que pesquisar semântica?
1.1 O que é pesquisa?
Por milhares de anos, as pessoas quiseram pesquisar entre documentos: pense nas enormes bibliotecas que contêm milhões de livros. Foi possível então procurar nesses livros graças às pessoas que os classificassem cuidadosamente por nomes de autores, data de publicação,… Os índices dos livros foram cuidadosamente construídos e foi possível encontrar livros pedindo a especialistas.Há 30 anos, a internet se tornou popular e, com ela, o número de documentos para pesquisar passou de milhões para bilhões. A velocidade com que esses documentos passaram de alguns milhares todos os anos para milhares todos os dias, não era mais possível indexar tudo manualmente.Foi quando sistemas de recuperação eficientes foram construídos. Usando a estrutura de dados apropriada, é possível indexar bilhões de documentos todos os dias automaticamente e consultá-los em milissegundos.A pesquisa é sobre atender a uma necessidade de informação. Começando por usar uma consulta de qualquer forma (perguntas, lista de itens, imagens, documentos de texto,…), o sistema de pesquisa fornece uma lista de itens relevantes. Os sistemas de pesquisa clássicos constroem representações simples a partir de texto, imagem e contexto e constroem índices eficientes para pesquisar a partir deles. Alguns descritores e técnicas incluem
As semelhanças de itens são um método clássico para encontrar itens semelhantes usando classificação e tendências
Embora esses sistemas possam ser dimensionados para quantidades muito grandes de conteúdo, eles geralmente sofrem de dificuldades para lidar com o significado do conteúdo e tendem a permanecer no nível da superfície.Essas técnicas clássicas de recuperação fornecem bases sólidas para muitos serviços e aplicações. No entanto, eles não conseguem entender completamente o conteúdo que estão indexando e, como tal, não podem responder de maneira relevante a algumas perguntas sobre alguns documentos. Veremos nas próximas seções como as incorporações podem ajudar.
1.2 O que é pesquisa semântica e o que pode ser construído com ela?
A principal diferença entre a pesquisa clássica e a pesquisa semântica é usar pequenos vetores para representar itens.
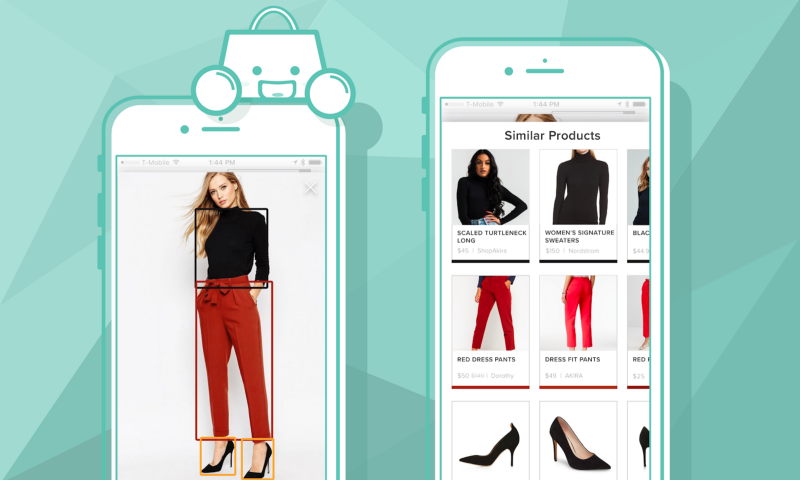
A pesquisa visual pode ser usada para procurar plantas PlantNet, mas também para procurar roupas
O uso de incorporações é poderoso: pode ser usado para criar sistemas que podem ajudar os usuários a encontrar itens de que gostam (música, produto, vídeos, receitas, …) usando muitos tipos de consultas. Ele não pode funcionar apenas em sistemas de pesquisa explícitos (inserindo uma consulta em uma barra de pesquisa), mas também em sistemas implícitos (produtos relevantes em sites de varejistas, notícias personalizadas em editores, postagens interessantes em plataformas sociais).Muitos tipos de sistemas podem ser construídos em cima da pesquisa.
Um sistema de pesquisa de texto leva como entrada uma consulta de texto e retorna resultados: pesquisa de roupas, músicas, notícias
Um sistema de pesquisa visual toma como entrada uma imagem e retorna itens semelhantes em comparação com esta imagem.
Um sistema de recomendação usa como entrada algum contexto, informações do usuário e retorna itens semelhantes que otimizam para um determinado objetivo: recomendar filmes, carros, casas
Redes sociais, redes de publicidade, mecanismos de busca especializados (pesquisa de produtos) usam técnicas de recuperação para fornecer as melhores informações
É possível pesquisar uma variedade de itens, qualquer coisa que tenha imagens, texto, áudio ou esteja disponível em um contexto. Exemplos populares de tais sistemas são a lente do Google, a recomendação da Amazon ou os mais novos para pesquisa de moda, pesquisa de plantas, …Em menor escala, pode ser interessante indexar suas fotos, suas mensagens, encontrar um programa de TV entre muitos, encontrar atores em um programa de TV, …
2. Design geral: como construir pesquisa semântica?
Um sistema de pesquisa semântica é composto por duas partes: um pipeline de codificação que constrói índices e um pipeline de pesquisa que permite ao usuário usar esses índices para pesquisar itens.
3 Pipeline de codificação: de itens a vetores e índices
O primeiro passo para construir um sistema de recuperação semântica é codificar itens em pequenos vetores (centenas de dimensões). Isso é possível para muitos itens e pode ser usado para indexá-los e pesquisar entre eles de forma eficiente.
3.1 Extraia dados relevantes
Os sistemas de recuperação podem codificar itens de muitos aspectos diferentes, por isso é importante pensar no que codificar. Alguns exemplos de itens para codificar são roupas, brinquedos, animais, notícias, músicas, filmes, receitas. Cada um deles tem características diferentes: eles podem ser expressos por como se parecem, como podem ser descritos, como aparecem entre outros itens.Todas essas informações podem ser codificadas como incorporações. Um eixo diferente para pensar é quantos itens codificar? Todos os itens são únicos ou faz mais sentido agrupá-los por características relevantes? Existem alguns itens que são mais relevantes e devem ser uma prioridade? Fazer essa escolha cedo pode ter consequências dramáticas para o resto do sistema.
Este personagem de Star Wars C-3PO pode ser codificado com uma imagem dele, uma descrição, como ele aparece em um gráfico (está em um filme de Star Wars, aparecendo na data desses filmes, …), quão popular ele é, mas também que ele aparece junto com R2-D2 com frequência, e tem uma voz robótica. Todas essas informações podem ser relevantes. Qual escolher pode afetar muito o desempenho do sistema.
Para um sistema de recomendação, as informações de co-ocorrência podem funcionar melhor, mas para um sistema de pesquisa visual, a imagem pode ser a mais relevante.
3.2 Codifique os itens
3.2.1 Conteúdo
Os itens podem ser codificados com base em seu conteúdo. As roupas podem ser bem representadas com imagens. Os sons são identificados por seu conteúdo de áudio. As notícias podem ser entendidas usando seu texto. Os modelos de aprendizagem profunda são muito bons em produzir representações de conteúdo que têm boas propriedades de recuperação.
As imagens podem ser representadas com incorporações (leia uma introdução sobre isso no meu post anterior). Redes como ResNet ou EfficientNet são realmente bons extratores de recursos para imagens, e muitas redes pré-treinadas estão disponíveis.Também não é apenas possível representar toda a imagem, mas também é possível usar segmentação ou detecção de objetos antes de aplicar o codificador de imagem.
A segmentação pode ser usada para extrair parte da imagem pixel por pixel, pode ser relevante para extrair camisas e calças de uma imagem de moda
A detecção é útil para extrair zonas retangulares das imagens
Uma diferença importante nos vários codificadores de imagem é qual perda eles estão usando. As redes convolucionais são frequentemente treinadas usando perda tripla, entropia cruzada ou, mais recentemente, perda contrastiva. Cada perda pode fornecer características diferentes para incorporações: perda tripla e perda contrastiva tentam montar itens semelhantes, enquanto a entropia cruzada reunirá itens da mesma classe. Muitos modelos pré-treinados são treinados na ImageNet com entropia cruzada para classificação de imagens, mas o aprendizado auto-supervisionado (simclr byol) está mudando rapidamente isso para tornar possível o treinamento não supervisionado sem classificação. Em um futuro próximo, os melhores codificadores podem não precisar de dados rotulados. Este tutorial em vídeo do CVPR2020 é muito bom para entrar em detalhes sobre recuperação de imagens.Ser capaz de codificar imagens como vetores torna possível construir muitos aplicativos: qualquer coisa que possa ser vista e assistida é algo que possa ser codificada. Pesquisa visual de moda, pesquisa de plantas, pesquisa de produtos são possíveis. A pesquisa em filmes e outros conteúdos de vídeo também se torna possível.
3.2.1.2 Texto
O texto também pode ser representado com incorporações. O texto pode ter várias formas e comprimentos: palavras, frases, documentos. A aprendizagem profunda moderna agora pode representar a maioria daqueles em representação poderosa.
Word2vec: a codificação de palavras é uma das formas mais populares de incorporação. A partir do contexto das palavras nos documentos, é possível inferir quais palavras estão mais próximas em significado às outras. Word2vec ilustrado e word2vec explicados introduzem bem o conceito e os métodos
Os transformadores são um método mais novo que torna possível codificar frases inteiras, levando melhor em conta as dependências entre muitas palavras nas frases. Alguns anos atrás, eles foram capazes de se tornar o estado da arte em muitas tarefas. O transformador ilustrado é uma introdução interessante a eles.
Arquitetura Bert: finalmente, a arquitetura Bert é um tipo especial de transformador que pode ser bem treinado em um ambiente multitarefa. Foi chamado de momento ImageNet de PNL. bert ilustrado é uma boa introdução a ele.
Na prática, alguns bons codificadores para texto podem ser:
Incorporações de palavras de luvas. Este pequeno exemplo de repositório word-knn que eu construí pode ajudar a começar rapidamente
O modelo labse para incorporações de frases é um modelo bert pré-treinado que pode codificar incorporações de até 109 idiomas em um único espaço
As incorporações de documentos podem ser representadas como a média das frases.
Ser capaz de codificar texto como vetores torna possível pesquisar artigos, descrição de filmes, títulos de livros, parágrafos da Wikipédia, … Muito conteúdo está disponível como texto, portanto, usar essas informações para um sistema de recuperação pode ser um dos primeiros passos a tentar.
3.2.1.3 E todos os outros conteúdos
Além do texto e da imagem, o conteúdo de áudio também pode ser codificado como incorporações (pense em aplicativos como o Shazam).Exemplos de Jina e vectorhub fornecem muitos bons exemplos de como codificar incorporações usando conteúdo
3.2.1.4 Escalando
Para codificar não apenas algumas centenas, mas bilhões de incorporações, trabalhos de lote como spark ou Pyspark podem ser realmente úteis. A maioria dos modelos de imagem e texto será capaz de codificar milhares de amostras por segundo. Codificar um bilhão de amostras em uma hora exigiria cerca de 300 executores.
A codificação de itens por seu conteúdo funciona bem e escala para bilhões de itens. Mas o conteúdo não é o único dado disponível, vamos ver como os outros itens podem ser codificados.
3.2.2 Distribuição: tendências
Itens como roupas, filmes e notícias geralmente estão presentes em sites visitados por muitos usuários. Os usuários interagem com os itens, gostam ou não, alguns itens são populares, alguns itens são vistos apenas por partes dos usuários e itens relacionados geralmente são vistos juntos. Tudo isso são dados de interação. Esses dados de interação podem ser usados para codificar itens. Isso é particularmente útil para definir incorporações para as quais a métrica de distância é baseada em como as pessoas interagem com esses itens sem precisar de nenhuma informação sobre seu conteúdo.
3.2.2.1 SVD
Um primeiro método para construir essa incorporação de comportamento é SVD: decomposição de valor singular.
No contexto em que para um conjunto de itens (notícias, produtos, restaurantes,…) classificações de usuários estão disponíveis, é possível calcular incorporações de usuários e itens. O primeiro passo é calcular uma matriz de similaridade de item de usuário e usando fatoração de matriz (SVD), incorporações de usuário e incorporações de itens são computadas. O svd de item de usuário é uma introdução simples a esse processo.
Outra configuração aparece quando é possível observar co-ocorrências entre itens. Um exemplo poderia ser produtos (roupas, casas, laptops, …) que são visualizados ou comprados juntos por um usuário. Essas co-ocorrências podem ser expressas com seu PMI e essa matriz item-item pode ser fatorada com SVD em incorporações de itens. Essas duas postagens de blog fornecem uma boa introdução.
Essa maneira de codificar itens em incorporações é particularmente poderosa para codificar as preferências e o comportamento do usuário em relação aos itens sem precisar de nenhum conhecimento sobre esses itens. Isso significa que ele pode funcionar em todos os idiomas e para itens onde nenhum conteúdo está disponível.
3.2.2.2 Incorporação de gráficos
Uma segunda maneira de codificar itens usando sua distribuição é a incorporação de gráficos.
Muitos conjuntos de dados podem ser representados como gráficos. Um bom exemplo é um gráfico de conhecimento. Wikidata e DBpedia, por exemplo, representam o conhecimento no mundo real como entidades como pessoas, empresas, países, filmes… e relações entre eles, como cônjuge, presidente, nacionalidade, ator.
Wikidata representa o conhecimento sobre as entidades mundiais
Isso forma um gráfico: entidades são nós no gráfico, e esses nós são ligados por arestas que são relações.
Existem muitos algoritmos interessantes e artigos recentes sobre incorporações de gráficos e redes neurais de gráficos em geral (este canal de telegrama é ótimo para seguir o tópico), mas um simples e escalável é o Pytorch Big Graph. Este ajudante que construí com um colega pode ajudar a construir grandes conjuntos de dados gráficos para PBG e visualizar alguns resultados knn.
Essa representação de dados como um gráfico pode ser usada para construir incorporações para nós e transformação para arestas que possibilitam ir de um nó para o outro. A ideia é aprender a mapear um nó para outro nó usando ambas as incorporações de nós e uma transformação que pode ser aprendida para a borda. Tal transformação pode ser uma tradução. Isso dá resultados surpreendentemente bons para prever a próxima vantagem.
O PBG possibilita aprender a transformação entre bilhões de incorporações
A contribuição do Pytorch Big Graph é particionar os nós e arestas para que seja possível aplicar esse aprendizado a centenas de milhões de nós e bilhões de arestas.
Os gráficos são muito versáteis e podem não apenas representar gráficos de conhecimento, mas também links entre usuários, produtos, restaurantes, filmes, … Usar incorporações de gráficos pode ser uma boa maneira de usar a distribuição de itens para codificá-los.
3.2.3 Composição e multimodal
Agora temos incorporações de itens de várias perspectivas, e eles podem oferecer informações complementares. Como uma peça de roupa se parece, como os usuários interagem com ela e como ela é descrita podem ser relevantes.
Como essas incorporações podem ser combinadas em uma única?
Concatenação: concatenar as incorporações é um método básico que funciona surpreendentemente bem. Por exemplo, a concatenação de incorporações de texto e imagem torna possível pesquisar um item usando seu texto, sua imagem ou ambos.
Modelo multimodal: a aprendizagem profunda da visão e da linguagem está se tornando muito popular, e muitos modelos (imagebert, vilbert, uniter, vl-bert, veja esta demonstração interessante) propõem aprender com a linguagem e o texto, para produzir representações de modelos cruzados.
Ajustando uma rede para uma tarefa específica usando várias incorporações
A composição é uma ferramenta poderosa e pode ser usada para ter uma visão completa dos itens a serem codificados.
3.2.4 Popularidade
Um tópico importante a ser considerado nos sistemas de recuperação e recomendação é a popularidade dos itens. Mostrar itens impopulares geralmente resulta em resultados não relevantes.
Uma maneira simples de resolver esse problema é adicionar um termo de popularidade à incorporação. Por exemplo, o último componente pode ser o inverso do registro do número de visualizações desse item. Dessa forma, a distância L2 entre uma consulta com um 0 no componente de popularidade classificará em primeiro lugar os itens mais populares. Isso pode ajudar a remover alguns dos itens impopulares dos principais resultados, mas isso não é perfeito, pois o trade-off entre semelhança e popularidade deve ser definido manualmente.
Treinar as incorporações para um objetivo específico é uma maneira melhor de resolver isso.
3.2.5 Treinamento
Para codificar itens, modelos de conteúdo pré-treinados e métodos baseados em distribuição funcionam bem, mas para ajustar as incorporações para uma determinada tarefa, a melhor maneira é treinar um novo modelo para isso.
Muitas tarefas podem ser consideradas para treinar incorporações: baseadas em conteúdo, baseadas em distribuição e para objetivos mais específicos, como engajamento, cliques ou talvez até mesmo felicidade do usuário.
3.2.5.1 Treinamento específico de imagem
As incorporações de imagens podem ser treinadas com tarefas como classificação, identificação, segmentação. Groknet é um bom exemplo de um grande sistema para aprender incorporações de imagens com objetivos específicos… Ele aprende em muitos conjuntos de dados díspares para muitas tarefas diferentes.
Groknet: usando um tronco de visão para treinar incorporações com muitos tipos de conjuntos de dados e perdas.
FaceNet é outra maneira simples de treinar incorporações de imagens além da classificação. A perda tripla permite que ele aprenda um tipo específico de incorporação de imagem: incorporação de rosto. Isso pode ser reutilizado para outros exemplos, como incorporação de ursos de treinamento
3.2.5.2 Treinamento específico do texto
Bert é um ótimo exemplo de um modelo que pode ser ajustado e reutilizado para vários objetivos. Em particular, a biblioteca de transformadores huggingface e a biblioteca de transformadores thesentence com base nela são ótimas para ajustar um modelo de texto para um caso de uso específico. Centenas de arquiteturas de transformadores diferentes estão disponíveis lá com dezenas de configurações de treinamento.
3.2.5.3 Distribuição: treinamento específico de recomendação
Incorporações de ajuste fino para recomendação
Outra configuração é um modelo de treinamento para recomendação. Isso pode funcionar muito bem para ir além do SVD e treinar incorporações de produtos e usuários. A biblioteca criteodeepr com seu blog que o acompanha é uma boa introdução a este tópico. Os recomendadores do Tensorflow são outro bom ponto de entrada.
3.2.5.1 E muito mais
Além dessas configurações de treinamento específicas, as incorporações de treinamento são o núcleo da aprendizagem profunda e da aprendizagem de representação. Pode ser aplicado em muitos ambientes e para muitos objetivos. Alguns exemplos interessantes são:
StarSpace, um projeto do Facebook para aprender incorporações de imagens, texto, gráfico e distribuição para vários objetivos
Incorporação de receitas um exemplo de um projeto para aprender incorporações de receitas a partir de ingredientes, instruções e imagens
Para se aprofundar mais neste tópico de treinamento de redes neurais para recuperação de informações, esses slides do ecir2018 estão bastante completos.
3.3 Construa índices relevantes
Uma vez que as incorporações são construídas, precisamos de uma maneira de olhar entre elas rapidamente. Isso pode ser alcançado graças ao algoritmo k do vizinho mais próximo. A versão simples consiste em calcular uma distância entre um vetor e todos os vetores do conjunto de dados. Isso pode ser melhorado muito usando algoritmos aproximados de k vizinhos mais próximos.
Usando a implementação correta dos índices knn, é possível procurar os vizinhos mais próximos de uma incorporação a partir de um conjunto de bilhões de vetores em milissegundos. Graças às técnicas de quantização, isso pode caber em apenas alguns GB de memória.
3.3.1 O que indexar, quantos índices?
Em termos de desempenho, as coisas importantes a serem otimizadas ao construir índices são:
Latência: quanto tempo leva para um índice retornar resultados?
Lembre-se: quantos dos resultados de um knn de força bruta são encontrados no resultado do índice?
Memória: quão grande é o índice, quanta memória é necessária para mantê-lo na ram?
Em termos de relevância de pesquisa, pode ser importante particionar as incorporações nas dimensões certas. Por exemplo, os itens podem ser particionados por categorias amplas (calças, camisetas,…) para um aplicativo de pesquisa visual de moda. Esse particionamento pode ter consequências ao construir os índices, por isso é melhor decidir cedo.
3.3.2 Aproximado knn e bibliotecas
Para escolher a melhor maneira de construir índices, o número de incorporações é um bom discriminador.
Alguns exemplos de algoritmos apropriados podem ser:
Para menos de mil incorporações, uma busca de força bruta faz sentido
Por menos de um milhão, um algoritmo rápido, mas não eficiente em termos de memória (como HNSW) é apropriado
Por menos de um bilhão, a quantização (usando k-means e fertilização in vitro) se torna importante
Para um exemplo trilhão, a única solução são os índices em disco
Alguns algoritmos para calcular knn aproximado são:
Um knn ingênuo: que pode ser implementado em O(nlog(k)) com uma fila de prioridade ou O(n) com quickselect ou introselect. Para poder calcular isso, é necessário armazenar todas as incorporações na memória.
HNSW: um algoritmo que constrói um gráfico de vizinhos. É O(log(N)) na pesquisa, mas não é exato. Leva cerca de duas vezes a memória das incorporações porque precisa armazenar o gráfico
FIV: o algoritmo de arquivo invertido consiste em dividir o espaço de incorporação em várias partes e usar k-means para encontrar uma aproximação de incorporação. É menos rápido que o HNSW, mas permite diminuir a memória exigida pelo índice tanto quanto necessário.
Para saber mais sobre todos os tipos de índices, recomendo ler esta página da documentação do faiss. Este tutorial do CVPR2020 se aprofunda sobre esses algoritmos, aconselho assisti-lo se você estiver interessado em entender os detalhes mais finos.
As bibliotecas que implementam esses índices incluem:
Faiss Uma biblioteca muito ampla que implementa muitos algoritmos e interfaces limpas para construí-los e pesquisar a partir deles
Hnswlib é atualmente a implementação mais rápida de HNSW. Altamente especializado e otimizado
Annoy é outro algoritmo knn, implementado pelo Spotify
Como o knn aproximado está no centro da recuperação moderna, é um campo de pesquisa ativo. Notavelmente, esses artigos recentes introduzem novos métodos que superam algumas métricas.
Scann do Google é um novo método que é de última geração, superando HNSW em velocidade e recall usando quantização anisotrópica
Catalisador do Facebook que propõe treinar o quantizador com uma rede neural para uma tarefa específica
Eu aconselho começar pelo faiss por sua flexibilidade e tentar outras bibliotecas para necessidades específicas.
3.3.3 Escala
Para ser capaz de escalar para muitas incorporações, as técnicas principais são:
Quantificação: as incorporações podem ser compactadas em índices de tamanho 1/100 e mais
Sharding: particionar os itens ao longo de uma dimensão, torna possível armazenar os índices em diferentes máquinas
Para escalar em termos de velocidade, a velocidade do índice é realmente importante (algoritmos como HNSW podem ajudar muito), mas servir também é crucial. Mais detalhes sobre isso na seção de serviço.
Em termos práticos, é possível construir um índice de 200 milhões de incorporações com apenas 15 GB de memória RAM e latências em milissegundos. Isso desbloqueia sistemas de recuperação baratos na escala de um único servidor. Isso também significa que, na escala de alguns milhões de incorporações, os índices knn podem caber em apenas centenas de megabytes de memória, que podem caber em máquinas de mesa e até mesmo dispositivos móveis.
3.3.4 Índices Knn como um componente de banco de dados
Bancos de dados existem em todos os tipos: bancos de dados relacionais, armazenamentos de chaves/valores, bancos de dados de gráficos, armazenamentos de documentos,… Cada tipo tem muitas implementações. Esses bancos de dados trazem maneiras convenientes e eficientes de armazenar informações e analisamos-las. A maioria desses bancos de dados fornece maneiras de adicionar novas informações e consultá-las pela rede e usar APIs em muitos idiomas. Esses bancos de dados em seu núcleo estão usando índices para torná-los rápidos para consultá-los. Os bancos de dados relacionais em seu núcleo usam mecanismos de armazenamento (como o InnoDB) que usam índices adaptados. As lojas de chaves/valor implementam índices baseados em hash compartilhados e distribuídos.
E se os índices knn pudessem ser integrados às implementações de banco de dados como apenas mais um tipo de índice?
Isso é o que é proposto por projetos como
Uma integração de pesquisa elástica de HNSW: eles propõem adicionar hnsw como parte do banco de dados geral de pesquisa elástica. Isso torna possível combinar a pesquisa knn com consultas rigorosas, consultas de texto e junções fornecidas pela pesquisa elástica
Unicorn, um sistema privado do Facebook que permite integrar a pesquisa knn em um banco de dados de gráficos. Como consequência, as consultas nesse gráfico podem ter partes usando consultas knn.
Além desses sistemas específicos, o que eu acho realmente interessante nesse conceito é a ênfase em tornar a construção de índices knn um processo simples que pode ser acionado facilmente:
A adição de novos dados aciona automaticamente a reindexação ou a adição direta de incorporações aos índices existentes
Escolhendo automaticamente o tipo certo de índice knn com base na restrição específica do sistema
4. Pipeline de pesquisa: de índices a sistemas de pesquisa semântica
O pipeline de pesquisa é a parte do sistema que geralmente é executada em uma configuração on-line e de baixa latência. Seu objetivo é recuperar resultados relevantes para uma determinada consulta. É importante que ele retorne resultados em segundos ou milissegundos, dependendo das restrições e para ocupar baixas quantidades de memória.
É composto por uma maneira de extrair dados relevantes de uma consulta, um codificador para transformar esses dados em incorporações, um sistema de pesquisa que usa índices construídos no pipeline de codificação e, finalmente, um sistema de pós-filtragem que selecionará os melhores resultados.
Ele pode ser executado em servidores, mas para uma quantidade menor de itens (milhões), também pode ser executado diretamente no lado do cliente (navegadores e dispositivos pequenos).
4.1 Extraia partes de consultas
A primeira parte do sistema consiste em pegar uma consulta como entrada e extrair dados relevantes dela para poder codificá-la como incorporações de consulta.
Alguns exemplos interessantes de consultas incluem procurar roupas semelhantes, procurar uma planta de uma foto, procurar músicas semelhantes de um registro de áudio. Outro exemplo pode ser uma lista de itens vistos pelos usuários.
A consulta pode assumir qualquer forma: uma imagem, texto, uma sequência de itens, áudio, …
Para poder codifico-lo da melhor maneira, várias técnicas podem ser usadas:
Para uma segmentação de imagem ou detecção de objetos pode ser relevante: extrair apenas roupas da foto de uma pessoa, por exemplo
Para texto, pode ser relevante extrair entidades nomeadas da consulta, pode fazer sentido aplicar a extensão de consulta para adicionar termos relevantes ou corrigir erros de digitação
Para uma lista de itens, agrupar os itens para selecionar apenas um subconjunto relevante pode ajudar
Segmentação de pessoas para extrair roupas
4.2 Codifique a consulta
Depois que os dados relevantes são extraídos da consulta, cada um desses elementos pode ser codificado. A maneira de codificá-lo geralmente é semelhante à maneira como as incorporações dos índices são construídas, mas é possível aplicar técnicas que são relevantes apenas para a consulta.
Por exemplo:
Uma média de vários elementos para obter resultados relevantes para uma lista de itens
Agrapee os pontos da consulta e escolha um cluster como a consulta
Use modelos mais complexos para gerar consultas apropriadas no mesmo espaço, usando modelos de transformador para resposta a perguntas (veja DPR), ou transformações de incorporações de gráficos (veja PBG), por exemplo
Para o caso de uso de recomendação, é possível treinar diretamente um modelo que produzirá as melhores consultas para um determinado objetivo, veja este post do blog do criteo como exemplo.
4.3 Pesquise os índices certos
Dependendo do tipo de consulta, pode ser relevante construir não apenas um índice, mas vários. Por exemplo, se a consulta tiver uma parte de filtro para uma determinada categoria de item, pode fazer sentido construir um índice específico para esse subconjunto de incorporações.
Aqui, selecionar o índice da Toyota tornou possível devolver apenas produtos relevantes desta marca.
4.4 Filtragem de postagens
Construir vários índices é uma maneira de introduzir filtragem rigorosa em um sistema, mas outra maneira é fazer uma grande consulta knn e pós-filtrar os resultados.
Isso pode ser relevante para evitar a construção de muitos índices
4.5 Porção
Finalmente, a construção de um aplicativo de serviço torna possível expor os recursos aos usuários ou outros sistemas. Graças às bibliotecas rápidas de k vizinhos mais próximos, é possível ter latências em milissegundos e milhares de consultas por segundo.
Há muitas opções para construir isso. Dependendo do estado e do escopo dos projetos, diferentes tecnologias fazem sentido:
Para experimentar inicialmente, a construção de um aplicativo de frasco simples com faiss pode ser feita em apenas 20 linhas de código
Usar um servidor adequado com frasco como gunicorn com gevent pode ser suficiente para atingir latências de milissegundos a milhares de qps
Para obter ainda mais desempenho, a construção de um serviço de serviço com linguagens nativas como ferrugem ou C++ pode ser feita. O benefício de usar uma linguagem nativa para esse tipo de aplicativo pode ser evitar custos de GC, já que o próprio índice knn é construído em C++, apenas o código de serviço precisa ser otimizado.
As bibliotecas Aknn são mais frequentemente construídas em c++, mas as ligações podem ser feitas com muitas linguagens (java, python, c#) manualmente ou com swig. Para integração com um aplicativo existente, isso pode ser o mais relevante em alguns casos.
4.6 Avaliação
A avaliação de um sistema de pesquisa semântica dependerá muito do caso de uso real: um sistema de recomendação ou um sistema de recuperação de informações pode ter métricas muito diferentes. As métricas podem ser amplamente divididas em duas categorias: métricas on-line e métricas off-line. As métricas on-line podem ser medidas apenas a partir do uso do sistema, muitas vezes em uma configuração de teste A/B. Para recomendação, em particular, a taxa de cliques ou diretamente a receita pode ser considerada, este documento explica alguns deles com mais detalhes. As métricas off-line podem ser calculadas a partir de conjuntos de dados off-line e exigem alguns rótulos. Esses rótulos podem ser implícitos com base em como os usuários interagem com o sistema (o usuário clicou nesse resultado?) ou explícitos (annotadores que fornecem rótulos). Algumas métricas off-line são gerais para todos os sistemas de recuperação, a página da Wikipedia sobre isso é bastante completa. As métricas frequentemente usadas incluem o recall, que mede o número de documentos relevantes que são recuperados, e o ganho cumulativo descontado que explica a classificação dos itens recuperados.
Antes de fazer análise quantitativa, construir uma ferramenta de visualização e analisar o resultado geralmente fornece insights úteis.
5. Soluções práticas para construir isso facilmente
5.1 Soluções de código aberto de ponta a ponta
Outra maneira de começar a criar aplicativos de pesquisa semântica é usar soluções de código aberto pré-existentes. Recentemente, várias organizações e pessoas os construíram. Eles variam em objetivos, alguns deles são específicos para uma modalidade, alguns deles lidam apenas com a parte knn e alguns tentam implementar tudo em um sistema de pesquisa semântica. Vamos anuná-los.
Jina é um projeto de código aberto de pesquisa semântica de ponta a ponta construído pela empresa de mesmo nome. Não é um único serviço, mas fornece boas APIs em python para definir como criar codificadores e indexadores, e um sistema de configuração YAML para definir fluxos de codificação e pesquisa. Ele propõe encapsular cada parte do sistema em contêineres docker. Dezenas de codificadores já estão disponíveis, e vários indexadores também são construídos em seu sistema. Ele também fornece tutoriais e exemplos sobre como construir sistemas de pesquisa semântica específicos.
Eu recomendo ler o grande post do blog da jina. Sua sintaxe e flexibilidade é o que o torna o mais interessante e poderoso.
Milvus é um serviço de pesquisa semântica focado na indexação, usando faiss e nmslib. Ele fornece recursos como filtragem e adição de novos itens em tempo real. A parte de codificação é deixada principalmente para os usuários fornecerem. Ao integrar várias bibliotecas aknn, ele tenta ser eficiente.
A pesquisa elástica é um banco de dados de indexação clássico, frequentemente usado para indexar categorias e texto. Agora tem uma integração hnsw que fornece indexação automática e uso de todos os outros índices estritos de pesquisa elástica. Se as latências em segundos forem aceitáveis, esta pode ser uma boa escolha.
O Vectorhub fornece muitos codificadores (imagem, áudio, texto, …) e um módulo python fácil de usar para recuperá-los. Tem uma rica documentação sobre a construção de sistemas semânticos e este pode ser um bom ponto de partida para explorar codificadores e aprender mais sobre sistemas semânticos.
Haystack é um sistema de ponta a ponta para resposta a perguntas que usa knn para indexação semântica de parágrafos. Ele se integra a muitos modelos de texto (transformadores de rosto abraço, DPR, …) e vários indexadores para fornecer um pipeline de resposta a perguntas completo e flexível. Isso pode servir como um bom exemplo de um sistema de pesquisa semântica específico de modalidade (rendrondo a perguntas de texto).
Esses projetos são ótimos para começar neste tópico, mas todos eles têm desvantagens. Pode ser em termos de escalabilidade, flexibilidade ou escolha de tecnologia. Para ir além da exploração e pequenos projetos e construir projetos de maior escala ou personalizados, muitas vezes é útil criar sistemas personalizados usando os blocos de construção mencionados aqui.
5.2 Do zero
Escrever um sistema de pesquisa semântica pode parecer uma tarefa enorme devido a todas as diferentes partes que são necessárias. Na prática, a versatilidade e a facilidade de uso das bibliotecas para codificação e indexação tornam possível criar um sistema de ponta a ponta em algumas linhas de código. O repositório de incorporação de imagens que eu construí pode ser uma maneira simples de começar a construir um sistema do zero. Você também pode verificar a pequena palavra knn que eu construí como um exemplo simples. O ajudante PBG que construí com um colega também pode ajudar a inicializar o uso de incorporações de gráficos. Este vídeo do CVPR2020 é outro bom tutorial para começar com isso.
De todos os componentes que apresentei neste post, muitos são opcionais: um sistema simples só precisa de um codificador, um indexador e um serviço de serviço simples.
Escrever um sistema do zero pode ser útil para aprender sobre ele, para experimentação, mas também para integrar tal sistema em um ambiente de produção existente. Segmentar a nuvem pode ser uma boa opção, veja este tutorial do google cloud. Também é possível construir esse tipo de sistema em qualquer tipo de sistema de produção.
6. Conclusão
6.1 Além da pesquisa: aprendizado de representação
Além da construção de sistemas de pesquisa semântica, sistemas de recuperação e incorporações fazem parte do campo mais amplo do aprendizado de representação. O aprendizado de representação é uma nova maneira de construir software, às vezes chamado de software 2.0. As incorporações são as partes centrais das redes neurais profundas: elas representam dados como vetores em muitas camadas para eventualmente prever novas informações.
O aprendizado de representação fornece incorporações para recuperação e pesquisa semântica, mas, em alguns casos, a recuperação também pode ajudar no aprendizado de representação:
Usando a recuperação como parte do treinamento: em vez de pré-gerar exemplos negativos (para um sistema que usa uma perda tripla, por exemplo), um sistema de recuperação pode ser usado diretamente no treinamento (isso pode ser feito, por exemplo, com a integração entre faiss e PyTorch)
Usando a recuperação como uma maneira de criar conjuntos de dados: exemplos semelhantes podem ser recuperados como parte de um pipeline de aumento de dados
6.2 O que vem a seguir?
Como vimos neste post, os sistemas de recuperação são fáceis de construir e realmente poderosos, encorajo você a brincar com eles e pensar em como eles poderiam ser usados para muitos aplicativos e ambientes.
A busca e recuperação semântica são áreas de pesquisa ativas e muitas coisas novas aparecerão nos próximos anos:
Novos codificadores: o conteúdo 3D está sendo desenvolvido rapidamente, tanto com bibliotecas como PyTorch 3d quanto com artigos impressionantes como PIFuHD
A quantificação e a indexação também estão melhorando rapidamente com artigos como Scann e Catalyzer
O treinamento de ponta a ponta e a representação multimodal estão progredindo rapidamente com a visão e a linguagem tendo muito progresso: em direção a uma maneira generalizada de construir qualquer representação?
Onde os sistemas de recuperação podem viver? Até agora, eles eram principalmente localizados em servidores, mas com o progresso do aknn e da quantização, quais aplicativos eles podem desbloquear nos dispositivos do usuário?
Os sistemas de pesquisa semântica também estão progredindo rapidamente: centenas de empresas estão construindo-os, e vários bons sistemas de código aberto estão começando a surgir
A empresa SpaceX de Elon Musk sofreu um revés quando seu colossal novo foguete, Starship, explodiu em seu voo inaugural.
Ninguém se feriu no teste não tripulado que decolou da costa do Texas na manhã de quinta-feira, horário local.
Após dois a três minutos de voo, o foguete – o maior já desenvolvido – começou a perder o controle e logo foi destruído por cargas a bordo.
O Sr. Musk declarou que sua empresa tentará novamente em alguns meses.
Os engenheiros da SpaceX ainda classificam a missão de quinta-feira como um sucesso. Eles preferem “testar cedo e frequentemente” e não têm medo de cometer erros. Eles terão coletado uma grande quantidade de dados para preparar o próximo voo. Um segundo Starship já está quase pronto para voar.
“Parabéns equipe @SpaceX por um emocionante teste de lançamento do Starship! Aprendemos muito para o próximo teste de lançamento em alguns meses”, tweetou Musk.
A Federal Aviation Administration, que autoriza lançamentos de foguetes nos EUA, informou que supervisionará uma investigação sobre o incidente. Um porta-voz disse que isso é prática padrão quando um veículo é perdido durante o voo.
O empresário tentou moderar as expectativas antes do lançamento. Apenas fazer o veículo decolar sem destruir a infraestrutura da plataforma de lançamento já seria considerado “uma vitória”, ele disse.
Seu desejo foi atendido. O Starship deixou seu complexo de lançamento na fronteira EUA-México e ganhou velocidade enquanto se dirigia para o Golfo do México. Mas ficou evidente em um minuto ou mais que nem tudo estava correndo conforme o planejado.
Enquanto o foguete subia cada vez mais, podia-se ver que seis dos 33 motores na base do veículo haviam sido desligados ou apagados.
E três minutos após o voo, era bastante claro que o fim estava próximo. Quando as duas metades do veículo deveriam estar se separando, na verdade, ainda estavam conectadas – e desviando do curso.
Quatro minutos após o lançamento, quando o Starship estava perdendo altitude, uma grande explosão rasgou o céu azul, resultado dos computadores acionando o Sistema de Término de Voo (FTS) do veículo.
“Com um teste como este, o sucesso vem do que aprendemos, e hoje aprendemos uma quantidade imensa sobre o veículo e os sistemas terrestres que nos ajudarão a melhorar em futuros voos do Starship”, disse a SpaceX em um comunicado.
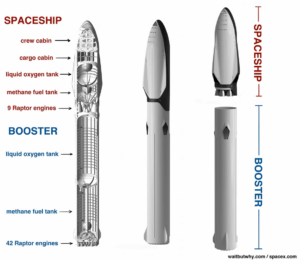
O segmento superior do Starship, também conhecido como a nave, já havia voado anteriormente em saltos curtos, mas esta foi a primeira vez que foi lançado com seu estágio inferior.
Este imenso propulsor, simplesmente chamado de Super Heavy, foi disparado enquanto estava preso ao seu suporte de lançamento em fevereiro. No entanto, seu conjunto de motores naquela ocasião foi reduzido à metade de sua capacidade.
Se, como prometido, a SpaceX utilizou 90% da força na quinta-feira, o estágio deveria ter fornecido algo próximo de 70 meganewtons.
Isso é o dobro da força produzida pelo foguete Saturn V, que famosamente enviou homens à Lua nas décadas de 1960 e 70.
O Starship pode não ter destruído sua plataforma de lançamento, mas fotos posteriores indicaram que a partida vigorosa causou uma boa quantidade de danos às superfícies de concreto.
O plano para a missão era enviar a nave para uma revolução quase completa da Terra, terminando com um pouso no Pacífico, a algumas centenas de km ao norte do Havaí.
Não havia expectativa de que a nave ou o Super Heavy fossem recuperados. No entanto, a longo prazo, esse é o plano. A ideia é pousar ambas as metades, reabastecê-las e lançá-las novamente – repetidamente.
Se isso puder ser alcançado, será transformador.
O Starship tem uma capacidade de carga projetada para órbita de mais de 100 toneladas por voo. Quando isso é aliado ao baixo custo de operação – principalmente, apenas o custo do combustível – deverá abrir a porta para um futuro empolgante.
“Na indústria, certamente há uma expectativa muito alta quanto ao potencial desse veículo para inovação”, disse a consultora espacial Carissa Bryce Christensen.
“Sua imensa capacidade, do ponto de vista comercial, pode ser significativa. Um veículo muito grande que é aprovado para humanos pode ser importante para o surgimento do turismo espacial. O outro elemento é o veículo ser barato. Então, temos um veículo com dois aspectos transformadores – capacidade massiva e, potencialmente, a um preço muito baixo”, disse a CEO da BryceTech à BBC News.
O empresário inicialmente usará o Starship para lançar milhares de satélites adicionais para sua constelação de internet de banda larga no céu – Starlink.
Apenas quando os engenheiros estiverem confiantes na confiabilidade do veículo, eles permitirão que as pessoas voem no foguete.
A primeira missão já foi organizada. Será comandada pelo bilionário empresário americano e piloto de jato rápido Jared Isaacman. Ele já voou para o espaço em uma cápsula Dragon da SpaceX.
O primeiro voo ao redor da Lua será realizado pelo bilionário japonês da moda Yusaku Maezawa. Ele levará oito artistas com ele como parte de seu projeto DearMoon.
A agência espacial americana, NASA, quer usar uma versão do Starship para pousar seus astronautas na superfície da Lua.