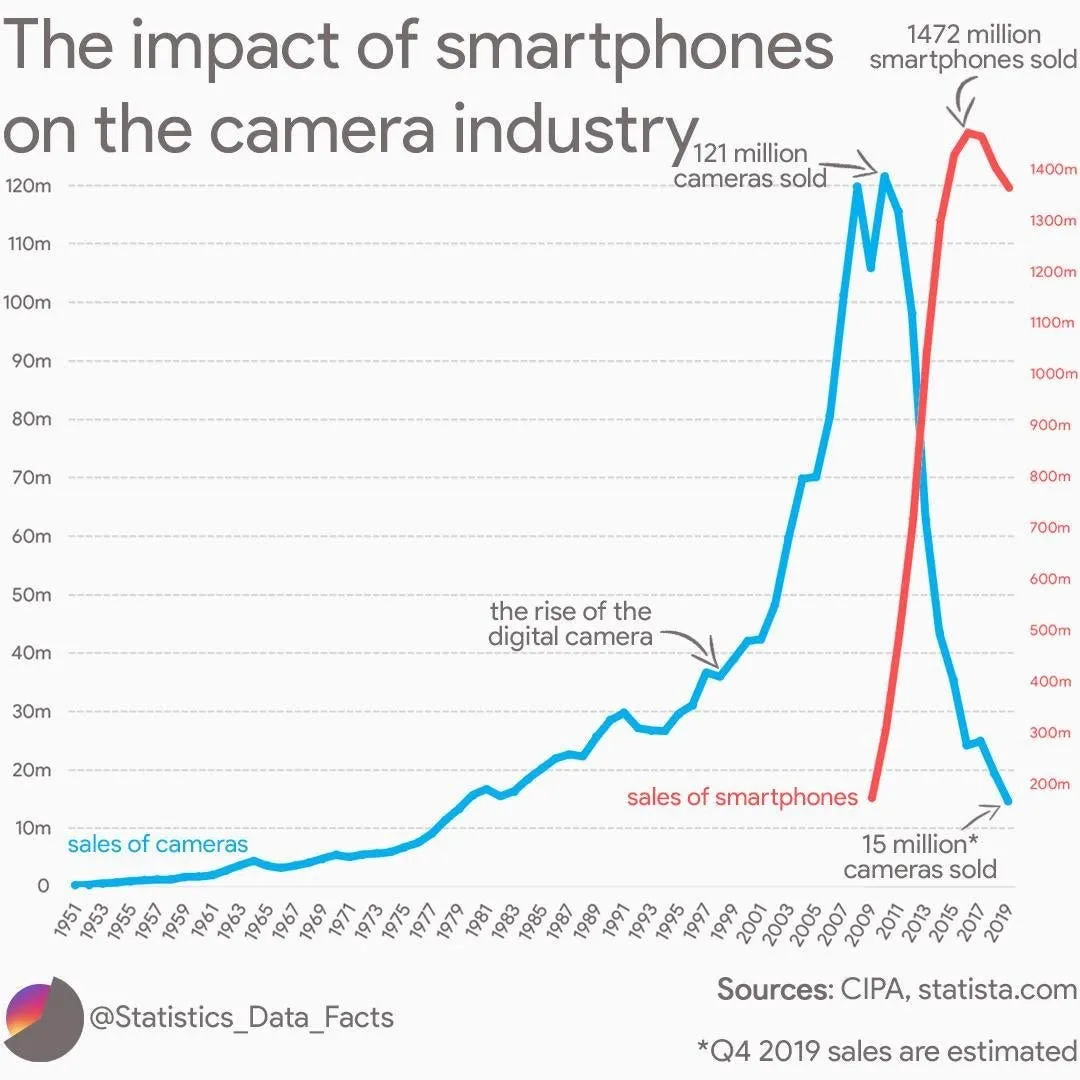
Veja este gráfico, ilustrando a ascensão e queda das câmeras digitais, e seu colapso desencadeado pela ubiquidade dos smartphones. Este gráfico é incrível, é claro, e captura a histórIA simples da ruptura tecnológica em um visual. É tão fácil! Só não se deixe perturbar.
Claro que é aproprIAdo começar um ensaio sobre a próxima disrupção da AI com um gráfico como este, mas honestamente é um clichê. Duh. Chato. Todos nós temos. Afinal, todos leram os mesmos livros de negócios, ouvem os mesmos podcasts e conhecem o mesmo jargão e as mesmas previsões. Na verdade, todas essas indústrIAs tradicionais legadas hoje em dAI são compostas por uma série de millennIAls e MBAs voltados para a tecnologIA que leram os estudos de caso relevantes da Harvard Business.
Sabemos que a disrupção da AI está chegando para muitas indústrIAs. A “AI Horde” , composta por milhares de startups de IA apoIAdas por vc, está começando a ir atrás de todas as indústrIAs como uma tecnologIA de computação geral que pode substituir e aumentar a mão de obra. Então, o que acontece a seguir, enquanto elas competem com as tradicionais?
“A IA vai perturbar Hollywood!!!” — Sério? Vai?
Para dar um exemplo de uma única indústrIA, role o suficiente nas mídIAs socIAis e você verá uma previsão como essa:: “A IA vai perturbar Hollywood!!!” Esse tipo de afirmação geralmente é acompanhado de um vídeo incrível de 30 segundos que dá uma amostra do que há de mais recente em IA — a saída de um monte de modelos de geração de vídeo, síntese de fala e música de IA, tudo cortado de uma forma que é altamente divertida por 30 segundos. E a previsão parece certa. E é realmente incrível o quão rápido os modelos de vídeo de IA de geração estão progredindo — hoje a saída ainda é um pouco instável, mas a taxa de melhorIA é incrível.
Vamos nos aprofundar neste exemplo específico de vídeo de IA e Hollywood/YouTube/etc, mas isso está sendo dito para muitas indústrIAs que estão pensando em IAI. E eu quero dar a visão da startup de IA, não a visão do titular. Esta é uma abordagem diferente porque a teorIA da disrupção e o ponto de vista apresentado no Dilema do Inovador são focados em como um titular deve reagir melhor e proteger uma categorIA de produto bem definida. O POV faz sentido porque a maiorIA das teorIAs de gestão existe para perpetuar os titulares, e os MBAs são contratados para gerencIAr de forma intermedIArIA grandes e duradouros conglomerados.
Compare isso com uma startup totalmente nova, que tem um POV radicalmente diferente. A startup está apenas tentando sobreviver. Ela está tentando encontrar/escalar o ajuste do mercado de produtos e navegar em um sistema complexo de nichos e mercados, tentando encontrar uma base em pelo menos um, para que possa continuar a obter mais financIAmento e continuar sua jornada.
O titular pensa em defesa e está tentando defender seu castelo particular. Eles perguntam, como eu protejo minha posição específica em meu setor enquanto startups de AI tecnologicamente disruptivas entram nele?
As startups de IA pensam em ofensiva e agem como uma Horda de IA bárbara, explorando, sondando e recuando, tentando descobrir o que funcionará entre muitos alvos possíveis. Elas atacarão qualquer castelo que pareça fraco e mudarão para outro se não parecer fácil. Elas perguntam: se eu puder construir produtos com essa nova tecnologIA, qual mercado devo perseguir onde os concorrentes são fracos? Devo dobrar onde estou ou mudar para atacar outro? Atacar os titulares diretamente ou tentar vender ferramentas para eles? Optar pelo premium e white glove ou construir algo mais simples e de baixo custo?
É por isso que a situação entre AI e Hollywood é tão interessante.
As grandes escolhas para vídeo de IA
As próximas decisões da “AI Horde” são complexas. Vamos afirmar que a tecnologIA de geração de vídeo de IA chegará lá eventualmente, e em breve estaremos aprecIAndo o vídeo em muitos formatos. Antes desse resultado inevitável, digamos que você é uma nova equipe de startups habilidosa tentando tirar o melhor proveito dessa tendêncIA que está por vir.
A multidão de decisões pode começar assim:
Devemos trabalhar dentro do ecossistema existente?
Vender ferramentas para empresas de entretenimento existentes;
CrIAr filme/TV e vender o conteúdo (“Pixar para IA”);
Compre um estúdio de cinema/TV existente e integre verticalmente a IA.
Ou deverIAmos mirar no ecossistema de mídIA socIAl?
Venda ferramentas para crIAdores;
Torne-se um novo tipo de crIAdor que usa IA para crIAr muito conteúdo;
Desempenhar alguma outra função no ecossistema existente (ex.: crIAr vídeos de AI etc.).
Ou construir algo novo que exista de forma independente?
Crie um novo aplicativo que use IA para interromper uma categorIA existente (como IA ReelShort);
Inove em um novo formato que priorize a IA (interativo? companheiros? um novo tipo de experiêncIA semelhante a um jogo?);
… e muito mais.
Essas são algumas das grandes escolhas, mas, na verdade, há um número infinito de decisões e sub decisões. PoderIAmos adicionar ainda mais detalhes sentando em pufes e fazendo mais brainstorming, mas este é um bom lugar para começar.
Imagine-se como uma nova startup de IA tentando descobrir onde atacar. Há castelos defendendo cada linha com marcadores na lista, o que é muito ruim por um lado, já que agora todo mundo leu os mesmos livros e as pessoas estão rapidamente escrevendo longos memorandos sobre a ameaça da AI. Mas, por outro lado, toda a vantagem de fazer parte da Horda da AI é que você é pequeno e rápido e pode atacar onde quer que seja fraco. E, tirando isso, muitas dessas balas são B2B e você pode simplesmente armar os caras grandes com armas para afastar a horda da IA.
Trabalhar com os titulares? Forma fraca X forma forte?
Dependendo dos seus interesses e histórico anterior, você pode ter atração ou aversão à interação com os participantes da indústrIA titular — para fins deste exemplo, estamos falando especificamente de Hollywood. (Eu me pego detestando ideIAs de startups que dependem desses titulares para adotar tecnologIA, já que eles têm uma longa histórIA e cultura de evitá-la sempre que podem, o que eu discuti aqui: Por que Hollywood e os jogos lutam com AI ). Mas isso vem com uma grande vantagem, que é que eles têm dinheiro e motivação. Eles também têm marcas, personagens e franquIAs bem conhecidas e amadas. Teoricamente, uma nova startup de IA poderIA fechar alguns negócios incríveis e dar um salto inicIAl em sua jornada.
Então aqui estão algumas maneiras de abordar o trabalho com Hollywood:
Pixar para IA, também conhecido como um novo estúdio de IA de Hollywood : se uma startup de IA puder hibridizar com um estúdio, então teoricamente alguém poderIA crIAr a próxima grande ideIA de filme, vendê-la para um grande estúdio (Sony, Paramount, Warner Bros e similares) e receber financIAmento para fazer o filme sem levantar capital de risco adicional. Isso gerarIA receita, e a startup do estúdio de IA poderIA continuar com uma série dessas, e se uma for um sucesso, pode se tornar uma maneira muito econômica de começar. Esta é, mais ou menos, a histórIA da Pixar, Toy Story e Disney, é claro. O maior desafio aqui é que você é obrigado, de uma perspectiva tecnológica, a construir algo no mais alto nível de qualidade para a tela de prata logo de cara, e eu não acho que Clayton Christensen aprovarIA nem serIA a coisa mais fácil de fazer. Mas essa opção está lá. Meu colega Jon Lai escreveu um ensaio sobre toda essa abordagem (e mais) e vale a pena ler. Uma questão interessante aqui é se você prefere apoIAr o time luminar de Hollywood que então vai e adota a tecnologIA, ou você prefere financIAr um fundador de tecnologIA que então vende para a indústrIA? Ambas são difíceis, mas, novamente, depende do seu gosto. Muitos vocês de tecnologIA preferem apoIAr o fundador de tecnologIA, mas o sonho, claro, é Ed Catmull com John Lasseter.
Estúdio habilitado para IA / tecnologIA : Há outra abordagem interessante aqui que é realmente comprar um estúdio de produção que já tenha um negócio, equipe e processo, e crIAr uma equipe de IA trabalhando junto com eles para construir/comprar/fazer parcerIAs agressivas em toda a tecnologIA necessárIA. Já estamos vendo isso sendo tentado no entretenimento, mas também em áreas como jurídica, suporte ao cliente, contabilidade e assim por dIAnte. Isso pode ser mais fácil de fazer do que tentar vender software.
Ferramentas de venda : Há uma tonelada de fluxos de trabalho na indústrIA cinematográfica que poderIAm usar ferramentas de IA hoje. Alguns são óbvios, como dublagem, internacionalização, etc. Esses são nichos legais que podem ser bons pontos de partida. Ou você pode olhar para outras questões, como gerencIAmento de ativos digitais ou pesquisa de vídeo. Ou edição, incluindo a capacidade de preencher lacunas de vídeo com conteúdo gerado por IA, em vez de refilmar. O caso de falha para tudo isso é que você está vendendo tecnologIA para empresas que têm orçamentos apertados e historicamente não foram grandes clientes. E talvez seus clientes também odeiem AI. Mas, por outro lado, se você puder tornar as pessoas mais produtivas e/ou seu novo aplicativo de AI funcionar com base em resultados (como a taxa total do projeto para dublar um filme, em vez de uma ferramenta de $/assento), então isso também pode funcionar. Mas também pode ser difícil.
Tudo isso pode funcionar, mas há um grande problema: há grandes eleitores em Hollywood que odeIAm completamente a IA. Dado que há tanta resistêncIA de sindicatos e crIAtivos contra a IA, essa abordagem funciona? Talvez os grandes estúdios se oponham a todos os usos de ferramentas de IA para apaziguar seus crIAtivos, e isso significa que eles não usarão ferramentas, não se envolverão com empresas que usam IA e não comprarão conteúdo crIAdo com IA. Mesmo que seja bom para eles financeiramente, uma das grandes diferenças entre a indústrIA do entretenimento e a indústrIA de software é que a primeira tem um controle sindical muito forte, e greves podem prejudicar um ano inteiro de filmes. Se você é pessimista, esta é sua opinião, e é por isso que Hollywood pode levar muito tempo (muito além do que é razoável) para adotar a IA, e em vez disso, toda a narrativa da IA acontecerá nas mídIAs socIAis e outras plataformas mais livres.
O ponto de vista otimista sobre isso é observar que, na verdade, há uma batalha entre os empresários e os crIAtivos na indústrIA do entretenimento — os primeiros realmente sabem que todo o seu modelo de negócios está quebrado e estão animados com a IA aumentando muito a quantidade, promovendo mais crIAtividade e reduzindo custos. Então, eles encontrarão um jeito. E também que Hollywood em si é muito fragmentada com um zilhão de estúdios e empresas de produção menores, muitos dos quais estão animados com a IA. (Fomos abordados por muitos!) Esses estúdios tecno-otimistas estão fadados a fazer um trabalho artístico incrível, talvez inicIAlmente com muito humano no circuito, e como resultado abrirão portas. Alguns dos principais distribuidores, como Netflix e Amazon, podem ser menos afetados por questões sindicais, então talvez eles pudessem comprar um novo filme de AI e abrir as comportas. Ou talvez distribuidores menores provem coisas em outras geografIAs, mostrem sucesso lá e, em seguida, tragam para os EUA conforme a janela de Overton muda.
Construindo para os nativos digitais
Se você decidir não construir para Hollywood, então você está construindo para a Internet, o que pode significar mídIA socIAl ou também potencIAlmente apenas construir seu próprio aplicativo. Isso pode se manifestar de várIAs maneiras diferentes:
“AI Cocomelon”: Uma versão é crIAr uma rede de mídIA de última geração como a “Cocomelon” (se você não ouviu, uma rede infantil muito valiosa foi vendida por US$ 3 bilhões recentemente) ou Mr. Beast ou algo semelhante, mas com conteúdo gerado por IA. Essa vantagem aqui é que você não precisa de ninguém para dar sinal verde para o conteúdo da maneira como Hollywood funciona — se as pessoas assistirem, você ganhará dinheiro. No entanto, o modelo de negócios é um fluxo residual de publicidade contra os vídeos por um longo período de tempo, em vez de um financIAmento inicIAl que ajuda a custear a construção do conteúdo. Portanto, inicIAlmente o conteúdo neste formato parecerá barato/de baixa qualidade, e eles precisam construir um portfólio enorme para gerar o fluxo de capital necessário para ter sucesso. É aqui também que as startups de geração de vídeo de IA que crIAm anime ou animação (infantil/adulto) serão ótimas porque essa tecnologIA está funcionando bem o suficiente agora — você só precisa do talento crIAtivo para crIAr novas histórIAs.
Ferramentas para crIAdores de mídIA socIAl : Já estamos vendo muitas delas, e é uma espécie de “venda de picaretas e pás” — ajudando crIAdores com ferramentas de vídeo que permitem que eles usem IA para crIAr novos conteúdos. Este é potencIAlmente um mercado muito grande, já que bilhões de pessoas agora usam mídIA socIAl e a maiorIA delas crIA conteúdo de uma forma ou de outra. No entanto, obvIAmente muito competitivo e muitos produtos utilitários não têm defensabilidade. (A propósito, eu pessoalmente adoro Captions (uma startup a16z) que realmente foi pioneira neste espaço!) Mas talvez essas ferramentas se tornem populares, sem dúvida, e tenho certeza de que haverá várIAs empresas bilionárIAs aqui
Novo aplicativo que é um IA ReelShort/TikTok/Twitch ou outro tipo de vídeo : Você pode crIAr um novo aplicativo, mas centralizá-lo na saída de vários modelos de vídeo de IA para atingir um dos muitos formatos de vídeo que já existem, por exemplo, um aplicativo IA TikTok, onde o modelo gera vídeos envolventes de 30 segundos, ou IA ReelShort, que é um aplicativo de conteúdo narrativo baseado em microtransações. Ou um IA Twitch, IA OnlyFans ou algo totalmente diferente. Todos esses são novos aplicativos autônomos que estão seguindo rapidamente os formatos de vídeo existentes. Talvez o usuário nem saiba que eles são gerados por IA.
Conteúdo interativo em tempo real, jogos e outras coisas novas : O ciclo de crIAção de Filme/TV funciona do jeito que funciona porque há um loop impossivelmente longo entre filmar o conteúdo, editar o conteúdo e assistir ao conteúdo. Se você pode gerar vídeo em tempo real, então o loop funciona de uma maneira completamente diferente. Talvez você gere o vídeo todo na hora, e a histórIA toda em tempo real também. Isso faz sentido particularmente em um mundo de jogos onde as pessoas querem fazer escolhas e ver o mundo (e personagens) reagir ao seu redor. Talvez haja algo entre um jogo e um filme. Talvez haja jogos que incorporem 10x o conteúdo cinematográfico, e sejam do seu próprio gênero. É difícil dizer o que se pode viver neste espaço de conteúdo interativo de última geração, mas esta é provavelmente uma das oportunidades mais interessantes, já que é onde o “conteúdo nativo de AI” realmente vive.
Claro que há mais ideIAs além disso, mas estou trapaceando um pouco aqui e dizendo que “novos formatos” são um espaço reservado para todas as coisas novas e legais que estamos fadados a ver. As abordagens nativas digitais são altamente atraentes para pessoas de fora de Hollywood, que não têm relacionamentos dentro do entretenimento. Também é atraente porque você pode crIAr conteúdo de baixa fidelidade — talvez conteúdo de meme ou curtas — e ganhar força. Não exige que você pule diretamente para o que pode ser mostrado na tela prateada imedIAtamente, o que é uma grande vitórIA. Mas, por outro lado, todos os principais problemas que as startups de tecnologIA enfrentam existem aqui — financIAmento escasso, canais de marketing caros, distribuição difícil para novos aplicativos, etc.
Uau, então falamos sobre muitas permutações agora. Uma nova startup de AI pode olhar para o labirinto à frente, com todas as opções potencIAis e caminhos sinuosos, e inevitavelmente se deparar com confusão. No final das contas, tudo bem — construir uma startup é pensar probabilisticamente, lançar e iterar e aprender e lançar novamente. Você pode começar querendo vender uma nova série animada para Hollywood, mas então perceber que prefere tentar vender a ferramenta. Mas talvez a base de clientes seja lenta para comprar, então você lança uma versão self-service que é então adotada pelos crIAdores de mídIA socIAl. Você pode rapidamente mudar de uma parte do labirinto para a outra.
Eis por que a teorIA da disrupção é tão limitante quando você olha para a visão de mundo do titular, agonizando se a Horda da AI irá atrás do seu mercado específico. A realidade é que a Horda está se movendo como uma onda, explorando cada nicho e cada nova tecnologIA. Eles são difíceis de defender porque é difícil até mesmo dizer qual deles está realmente indo atrás de você — é o aplicativo de curta-metragem de AI que suga todo o seu tempo de consumidor, afundando assim sua receita de assinatura de streaming? Ou é a empresa de ferramentas de IA que permite que todos os seus concorrentes criem conteúdo animado em 3D incrível como você faz há décadas, corroendo sua defensibilidade? A Horda da AI faz tudo isso.
Como isso se aplica a outras categorias
Para encerrar aqui, passei um bom tempo falando sobre Hollywood e os próximos modelos de geração de vídeo de IA, mas essa discussão poderIA ser aplicada a muitos outros mercados. Você frequentemente enfrenta algumas das mesmas escolhas:
Você trabalha no mercado existente ou tenta criar um novo?
É melhor vender ferramentas ou ir diretamente aos consumidores?
Você pode acelerar comprando um player existente e adicionando IA? Ou você começa uma nova empresa? Você começa com tecnólogos e adiciona especialistas de domínio, ou o contrário?
Você poderIA estar falando sobre muitas indústrias aqui — Marketing/RP, Contabilidade, ConsultorIA, Jurídico, Atendimento ao Cliente. E meu palpite é que múltiplas abordagens podem acabar funcionando.
Então, eu quero voltar à declaração original do começo do ensaio: “A IA vai perturbar Hollywood!!!” — vai? Eu acho que a IA vai perturbar, mas também será adotada e assimilada. Haverá novas experiências de consumo que competem diretamente com filmes/TV, mas também outras que competem indiretamente. Tudo vai acontecer.
Afinal, se você voltasse 20 anos no tempo e percebesse que o conteúdo online serIA grande, você poderia ter pensado: Vamos com força. As pessoas vão apenas assistir ao conteúdo da internet, não se preocupem com o que os formatos de mídIA atuais farão. No entanto, tanto a Netflix quanto o YouTube funcionaram. O ideal serIA apostar em ambos. Acho que a mesma coisa funcionará. A Horda da IA é tão poderosa que a veremos reinventar Hollywood, os jogos, o YouTube e muito mais. Ela afetará o conteúdo, sim, mas também as ferramentas de IA, as empresas habilitadas para IA e muito mais.
O Google essa semana apresentou o Phenaki, um modelo que pode sintetizar vídeos realistas a partir de sequências textuais.
A geração de vídeos a partir de texto é particularmente desafiadora devido a vários fatores, como alto custo computacional, durações variáveis de vídeo e disponibilidade limitada de dados de texto e vídeo de alta qualidade.Para resolver os dois primeiros problemas, Phenaki aproveita seus dois componentes principais:
Um modelo codificador-decodificador que compacta vídeos em embeddings discretos, ou tokens, com um tokenizer que pode funcionar com vídeos de duração variável graças ao uso de atenção causal no tempo.
Um modelo de transformador que traduz incorporações de texto em tokens de vídeo: usamos um transformador mascarado bidirecional condicionado a tokens de texto pré-computados para gerar tokens de vídeo a partir do texto, que são posteriormente destokenizados para criar o vídeo real.
Este vídeo de 2:28 minutos foi gerado usando uma longa sequência de prompts inseridos em uma versão mais antiga do Phenaki e depois aplicado a um modelo de super resolução.
Comandos:
“Visão em primeira pessoa de andar de moto em uma rua movimentada.”“Visão em primeira pessoa de andar de moto por uma estrada movimentada na floresta.”“Visão em primeira pessoa de andar de moto muito lentamente na floresta.”“Visão em primeira pessoa freando uma motocicleta na floresta.”“Correndo pela floresta.”“Visão em primeira pessoa de uma corrida pela floresta em direção a uma linda casa.”“Visão em primeira pessoa de uma corrida em direção a uma casa grande.”“Correndo pelas casas entre os gatos.”“O quintal fica vazio.”“Um elefante entra no quintal.”“O quintal fica vazio.”“Um robô entra no quintal.”“Um robô dança tango.”“Visão em primeira pessoa de correr entre casas com robôs.”“Visão em primeira pessoa da corrida entre as casas; no horizonte, um farol.”“Visão em primeira pessoa de voar no mar sobre os navios.”“Ampliar em direção ao navio.”“Diminua o zoom rapidamente para mostrar a cidade costeira.”“Diminua rapidamente o zoom da cidade costeira.”
Para resolver os problemas de dados, demonstramos que o treinamento conjunto em um grande corpus de pares imagem-texto e um número menor de exemplos de vídeo-texto pode resultar em generalização além do que está disponível apenas nos conjuntos de dados de vídeo.Quando comparado aos métodos anteriores de geração de vídeo, observamos que Phenaki poderia gerar vídeos arbitrariamente longos, condicionados a uma sequência de prompts de domínio aberto na forma de texto variável no tempo ou uma história. Até onde sabemos, esta é a primeira vez que um artigo estuda a geração de vídeos a partir de tais prompts variáveis no tempo.Além disso, observamos que nosso codificador-decodificador de vídeo superou todas as linhas de base por quadro atualmente usadas na literatura, tanto na qualidade espaço-temporal quanto no número de tokens por vídeo.
Esta história de 2 minutos foi gerada usando uma longa sequência de prompts, em uma versão mais antiga do Phenaki, e depois aplicada a um modelo em super resolução.
Comandos:
“Muito tráfego na cidade futurista.”
“Uma nave alienígena chega à cidade futurista.”
“A câmera entra na nave alienígena.”
“A câmera avança até mostrar um astronauta na sala azul.”
“O astronauta está digitando no teclado.”
“A câmera se afasta do astronauta.”
“O astronauta sai do teclado e caminha para a esquerda.”
“O astronauta deixa o teclado e vai embora.”
“A câmera se move além do astronauta e olha para a tela.”
“A tela atrás do astronauta mostra peixes nadando no mar.”
“Crash zoom no peixe azul.”
“Seguimos o peixe azul enquanto ele nada no oceano escuro.”
“A câmera aponta para o céu através da água.”
“O oceano e o litoral de uma cidade futurista.”
“Crash zoom em direção a um arranha-céu futurista.”
“A câmera amplia uma das muitas janelas.”
“Estamos em uma sala de escritório com mesas vazias.”
“Um leão corre em cima das mesas do escritório.”
“A câmera dá um zoom na cara do leão, dentro do escritório.”
“Amplie o leão vestindo um terno escuro em uma sala de escritório.”
“O leão que veste olha para a câmera e sorri.”
“A câmera se aproxima lentamente do exterior do arranha-céu.”
“Timelapse do pôr do sol na cidade moderna.”
Phenaki pode criar histórias visuais coerentes e longas a partir de uma cadeia de prompts, com uma resolução central de 128×128 pixels.
Queríamos entender se seria possível aproveitar a capacidade do Imagen Video de gerar vídeos de alta resolução com fidelidade fotorrealista sem precedentes e se beneficiar de seus módulos de super-resolução subjacentes para aprimorar a produção do Phenaki, com o objetivo de combinar os pontos fortes dessas duas abordagens em algo que poderia criar belas histórias visuais.
Para conseguir isso, alimentamos a saída do Phenaki gerada em um determinado momento (mais o prompt de texto correspondente) para o Imagen Video, que então executa a super-resolução espacial. Um ponto forte distinto do Imagen Video, em comparação com outros sistemas de super-resolução, é sua capacidade de incorporar o texto no módulo de super-resolução.
Para ver um exemplo que mostra como o sistema ponta a ponta funciona na prática, veja o exemplo anterior.
As legendas correspondentes a este exemplo são as seguintes:
Hurb fortalece sua jornada na nuvem com Machine Learning, Big Data e novas estratégias. A transformação propiciada pelo Google Cloud, que começou com ganho de escalabilidade e economia, culminou na melhor gestão e armazenamento de dados, garantindo a internacionalização dos processos.
Resultados do Google Cloud
Otimização de uma base de mais de 1,5 milhão de hotéis em todo o mundo
Redução de custos em 21%, com estimativa de chegar a 40% em alguns anos
Permissão de acesso a dados para mais de 700 colaboradores
Picos de utilização do aplicativo por 9 mil pessoas simultaneamente
Integração e colaboração das equipes com o Google Workspace
Redução do tempo de consulta de horas para segundos
O Hotel Urbano (Hurb) é uma das principais plataformas de viagens online do Brasil. A companhia tem como missão criar soluções para otimizar e tornar as viagens mais fáceis e acessíveis para todos, conectando pessoas e lugares. Com sede no Rio de Janeiro e atuação em todo o Brasil e no exterior, a empresa já conta com escritórios em Sorocaba (SP), Portugal e, em breve, no Canadá.
Acompanhando a premissa de inovação, a empresa, que nasceu ainda em servidores físicos, migrou para a nuvem em pouco tempo de existência. Entretanto, ainda assim havia a preocupação de resolver alguns desafios técnicos de escalabilidade para manter o crescimento do negócio de forma exponencial.
Desde que escolheu migrar sua infraestrutura para o Google Cloud, em 2016, a companhia deixou de se preocupar com diversas questões de infraestrutura. O time do Google foi essencial para auxiliar nesse caminho.
“Durante toda a migração para o Google Cloud, sempre recebemos apoio de Googlers para troca de várias informações sobre tecnologia. Quando precisamos de uma particularidade de um produto específico, conseguimos alinhar com os engenheiros do Google e, às vezes, se necessário, usamos a versão Beta cerca de quatro meses antes de estar disponível em produção. Em todo o processo não tivemos nenhum parceiro envolvido, somente a equipe do Google e a nossa equipe trabalhando em conjunto,” conta Leandro Souza, Head de Infraestrutura do Hurb.
Benefícios contabilizados em curto prazo
Desde a sua fundação, a empresa primava pelo estabelecimento de uma multizona para seus usuários e, ao mesmo tempo, pela robustez e elasticidade. Com a utilização do Google Kubernetes Engine, tornou-se possível assegurar o balanceamento de carga e distribuir os usuários nos microsserviços. Caso necessário, o recurso Horizontal Pod Autoscaler (HPA) dá conta da demanda, alocando mais contêineres para atender os usuários.
A nova infraestrutura também permitiu uma redução de servidores, com pico em número de usuários utilizando simultaneamente o aplicativo do Hurb. Outras conquistas com a nuvem foram a otimização do atendimento ao usuário e a maturidade para testar as ferramentas previamente para, então, disponibilizar aos utilizadores.
“Houve uma redução tão grande de erros, que alguns usuários até pensaram que o sistema não estava funcionando direito, pelas experiências anteriores à migração,” afirma o Head de Infraestrutura.
Como o Hurb já operava na nuvem, a necessidade de adaptação de infraestrutura foi facilitada. A equipe migrou algumas aplicações antigas em máquinas virtuais para contêineres e encaixou os mais de 86 microsserviços no novo sistema. Dois anos e meio após a migração, a empresa registrou uma redução de custos de 21%, e estima chegar a 40% nos anos seguintes.
“Ganhamos muito em escalabilidade e não precisamos adaptar a infraestrutura, só encaixar nossos mais de 86 microsserviços que tínhamos em 2019 no novo sistema de orquestração do Google Cloud. Também tivemos uma redução de 82 servidores para apenas 39, e chegamos a ter 9 mil pessoas simultaneamente no aplicativo.”
Projeto de expansão Global
Ao avaliar todos os bons resultados, a empresa entendia que ainda existiam alguns desafios técnicos que garantiriam o crescimento da plataforma de modo exponencial. Foi quando surgiu a ideia da aposta em Machine Learning e Big Data, em mais uma parceria com o Google Cloud, para a retomada das atividades do setor de turismo no período pós-pandemia. O objetivo era trazer inteligência ao trabalho dos colaboradores.
Como resultado, após a utilização das soluções em nuvem, o Hurb conseguiu resolver problemas de duplicidade de ofertas, democratizou o acesso às informações para os funcionários e passou a processar e armazenar dados de forma mais rápida e inteligente.
Atualmente, o Hurb vende uma diária a cada cinco segundos. Juntamente com a combinação entre o Google Geocoding API e sistemas proprietários de Machine Learning, a empresa passou a identificar estabelecimentos duplicados e semelhantes de seus diversos parceiros e a otimizar uma base de mais de 1,5 milhão de hotéis em todo o mundo.
Integrando a API Vision aos seus sistemas proprietários de dados, a companhia pôde compreender as milhões de imagens que representam seus produtos, assim como selecionar automaticamente a melhor imagem para seus clientes.
“A parceria com a nuvem proporcionou uma mudança cultural no Hurb. As nossas equipes passaram a ter acesso aos dados, acarretando uma performance baseada em métricas e, consequentemente, maior compromisso dos colaboradores com os resultados.”
Outro benefício da parceria foi a internacionalização da operação do Hurb, que foi possível graças à adoção da API Translation, solução do Google Cloud que traduz textos instantaneamente para mais de 100 idiomas.
Por sua vez, com as soluções Dataflow, Dataform e BigQuery, o processamento e o armazenamento de grandes volumes de dados tornaram-se uma realidade, instituindo uma forma muito mais rápida e inteligente, que fornece insights de negócios em tempo real para a empresa, sendo uma das primeiras empresas do mundo a adotar tal tecnologia.
Como saldo positivo, a companhia concedeu acesso a dados para mais de 900 colaboradores, reduziu o tempo de consulta aos dados de horas para segundos, passou a gerir mais de 2,5 mil tabelas com informações sobre o setor de turismo e reduziu a quantidade de erros em tabelas e o tempo para disponibilização dos dados.
Google Workspace para colaboração com o valor “Itá All about people”
Além de todas as implementações e mudanças propiciadas pela nuvem, o Google Workspace veio para complementar essa verdadeira jornada de bons resultados por parte do Hurb.
Nesse sentido, ao adotar as ferramentas do Google Workspace, os profissionais da empresa conseguem mensurar e compreender como as atividades são feitas, bem como gerir melhor o tempo.
O Planilhas é um dos exemplos que facilita a gestão dos dados e tarefas. Por meio de uma trilha de desenvolvimento de liderança, planejamento e novas ações, o Drive é utilizado para compartilhar documentos, assegurando o acesso das pessoas a todos os dados simultaneamente.
“Toda a nossa documentação é viva no Drive. Nós criamos um documento e o aprimoramos. Isso serve para parcerias e para nos nortear em diversos momentos dentro da companhia. Além disso, no Gmail, a comunicação é fluida com contas sincronizadas, o que nos poupa tempo.”
João Ricardo Mendes, CEO Global do Hurb
Sobre Hurb
Consolidando-se como destaque quando o assunto é plataforma e tecnologia para viagens online, Hurb busca alternativas para otimizar, simplificar e trazer fácil acesso às viagens, conectando pessoas e lugares e fazendo com que milhões de Brasileiros tenham sua primeira experiência de viagem.
Quando os cientistas examinaram pela primeira vez o tecido cerebral ao microscópio, viram uma bagunça impenetrável e confusa. Santiago Ramon y Cajal, o pai da neurociência moderna, comparou a experiência a entrar numa floresta com cem mil milhões de árvores, “olhando todos os dias para pedaços desfocados de algumas dessas árvores emaranhadas umas com as outras, e, depois de alguns anos de isso, tentando escrever um guia de campo ilustrado da floresta”, segundo os autores de The Beautiful Brain , livro sobre a obra de Cajal.
Hoje, os cientistas têm um primeiro rascunho desse guia. Num conjunto de 21 novos artigos publicados em três revistas, as equipas relatam que desenvolveram atlas de células cerebrais em larga escala para humanos e primatas não humanos. Este trabalho, parte da Iniciativa BRAIN dos Institutos Nacionais de Saúde , é o culminar de cinco anos de pesquisa. “Não é apenas um atlas”, diz Ed Lein, neurocientista do Allen Institute for Brain Science e um dos principais autores. “Isso está realmente abrindo um campo totalmente novo, onde agora é possível observar com resolução celular extremamente alta cérebros de espécies onde isso normalmente não era possível no passado.”
Bem-vindo de volta ao Checkup. Vamos conversar sobre cérebros.
O que é um atlas cerebral e o que o torna diferente?
Um atlas cerebral é um mapa 3D do cérebro. Já existem alguns atlas cerebrais, mas este novo conjunto de artigos fornece uma resolução sem precedentes de todo o cérebro para humanos e primatas não humanos. O atlas do cérebro humano inclui a localização e função de mais de 3.000 tipos de células em indivíduos adultos e em desenvolvimento. “Esta é de longe a descrição mais completa do cérebro humano neste tipo de nível, e a primeira descrição em muitas regiões do cérebro”, diz Lein. Mas ainda é um primeiro rascunho.
O trabalho faz parte da BRAIN Initiative Cell Census Network , que começou em 2017 com o objetivo de gerar um atlas abrangente de células cerebrais de referência em 3D para ratos (esse projeto ainda está em andamento). Os resultados divulgados em 12 de outubro faziam parte de um conjunto de estudos piloto para validar se os métodos utilizados em ratos funcionariam em cérebros maiores. Spoiler: esses métodos funcionaram. Muito bem, na verdade.
O que esses estudos iniciais descobriram?
O cérebro humano é muito, muito complexo. Eu sei, chocante! Até agora, as equipes identificaram mais de 3.300 tipos de células. E à medida que a resolução aumenta ainda mais (é nisso que estão trabalhando agora), é provável que descubram muito mais. Os esforços para desenvolver um atlas do cérebro do rato, que estão mais avançados, identificaram 5.000 tipos de células. (Para mais informações, confira estas pré-impressões: 1 e 2 )
Mas por baixo dessa complexidade existem alguns pontos em comum. Muitas regiões, por exemplo, compartilham tipos de células, mas os possuem em proporções diferentes.
E a localização dessa complexidade é surpreendente. A neurociência concentrou grande parte de sua pesquisa na camada externa do cérebro, que é responsável pela memória, aprendizagem, linguagem e muito mais. Mas a maior parte da diversidade celular está, na verdade, em estruturas evolutivas mais antigas, nas profundezas do cérebro, diz Lein.
Como eles fizeram esses atlas?
A abordagem clássica da neurociência para classificar os tipos de células depende da forma da célula – pense em astrócitos em forma de estrela – ou do tipo de atividade das células – como interneurônios de pico rápido. “Esses atlas celulares capitalizam um novo conjunto de tecnologias provenientes da genômica”, diz Lein, principalmente uma técnica conhecida como sequenciamento unicelular.
Primeiro, os pesquisadores começam com um pequeno pedaço de tecido cerebral congelado de um biobanco. “Você pega um tecido, tritura-o e traça o perfil de muitas células para tentar entendê-lo”, diz Lein. Eles entendem isso sequenciando os núcleos das células para observar os genes que estão sendo expressos. “Cada tipo de célula tem um conjunto coerente de genes que normalmente usa. E você pode medir todos esses genes e então agrupar todos os tipos de células com base em seu padrão geral de expressão genética”, diz Lein. Então, usando dados de imagem do cérebro do doador, eles podem colocar essa informação funcional onde ela pertence espacialmente.
Como os cientistas podem usar esses atlas de células cerebrais?
Tantas maneiras. Mas um uso crucial é ajudar a compreender a base das doenças cerebrais. Um atlas cerebral humano de referência que descreva um cérebro normal ou neurotípico poderia ajudar os pesquisadores a compreender a depressão, a esquizofrenia ou muitos outros tipos de doenças, diz Lein. Tomemos como exemplo o Alzheimer. Você poderia aplicar esses mesmos métodos para caracterizar os cérebros de pessoas com diferentes níveis de gravidade da doença de Alzheimer e depois comparar esses mapas cerebrais com o atlas de referência. “E agora você pode começar a fazer perguntas como: ‘Será que certos tipos de células são vulneráveis às doenças ou certos tipos de células são causais?’”, diz Lein. (Ele faz parte de uma equipe que já está trabalhando nisso .) Em vez de investigar placas e emaranhados, os pesquisadores podem fazer perguntas sobre “tipos muito específicos de neurônios que são os verdadeiros elementos do circuito que provavelmente serão perturbados e terão consequências funcionais”, ele diz.
Qual é o próximo passo?
Melhor resolução. “A próxima fase é realmente avançar para uma cobertura muito abrangente do cérebro dos primatas humanos e não humanos em adultos e no desenvolvimento.” Na verdade, esse trabalho já começou com a Cell Atlas Network da Iniciativa BRAIN , um projeto de cinco anos e US$ 500 milhões. O objetivo é gerar um atlas de referência completo dos tipos de células do cérebro humano ao longo da vida e também mapear as interações celulares subjacentes a uma ampla gama de distúrbios cerebrais.
É um nível de detalhe que Ramon y Cajal não poderia imaginar.
Vivemos em um mundo com uma explosão de informações. Há milhões de roupas, músicas, filmes, receitas, carros, casas, qual você deve escolher? A pesquisa semântica pode encontrar a certa para qualquer gosto e desejo!Neste artigo, vou apresentar o que é pesquisa semântica, o que pode ser construído com ela e como construí-la. Por exemplo, por que as pessoas procuram roupas?
Eles gostam da marca, da cor, da forma ou do preço. Todos esses aspectos podem ser usados para encontrar o melhor.A cor e a forma podem ser encontradas usando a imagem, e o preço e a marca são encontrados nas tendências.Imagens e tendências podem ser representadas como pequenos vetores chamados incorporações.
As incorporações são o núcleo da pesquisasemântica: uma vez que os itens são codificados como vetores, é rápido e eficiente procurar os melhores itens.Vou explicar como a pesquisa semântica funciona: codificar itens como incorporações, indexá-los e usar esses índices para pesquisa rápida, a fim de construir sistemas semânticos.
1. Motivação: por que pesquisar, por que pesquisar semântica?
1.1 O que é pesquisa?
Por milhares de anos, as pessoas quiseram pesquisar entre documentos: pense nas enormes bibliotecas que contêm milhões de livros. Foi possível então procurar nesses livros graças às pessoas que os classificassem cuidadosamente por nomes de autores, data de publicação,… Os índices dos livros foram cuidadosamente construídos e foi possível encontrar livros pedindo a especialistas.Há 30 anos, a internet se tornou popular e, com ela, o número de documentos para pesquisar passou de milhões para bilhões. A velocidade com que esses documentos passaram de alguns milhares todos os anos para milhares todos os dias, não era mais possível indexar tudo manualmente.Foi quando sistemas de recuperação eficientes foram construídos. Usando a estrutura de dados apropriada, é possível indexar bilhões de documentos todos os dias automaticamente e consultá-los em milissegundos.A pesquisa é sobre atender a uma necessidade de informação. Começando por usar uma consulta de qualquer forma (perguntas, lista de itens, imagens, documentos de texto,…), o sistema de pesquisa fornece uma lista de itens relevantes. Os sistemas de pesquisa clássicos constroem representações simples a partir de texto, imagem e contexto e constroem índices eficientes para pesquisar a partir deles. Alguns descritores e técnicas incluem
As semelhanças de itens são um método clássico para encontrar itens semelhantes usando classificação e tendências
Embora esses sistemas possam ser dimensionados para quantidades muito grandes de conteúdo, eles geralmente sofrem de dificuldades para lidar com o significado do conteúdo e tendem a permanecer no nível da superfície.Essas técnicas clássicas de recuperação fornecem bases sólidas para muitos serviços e aplicações. No entanto, eles não conseguem entender completamente o conteúdo que estão indexando e, como tal, não podem responder de maneira relevante a algumas perguntas sobre alguns documentos. Veremos nas próximas seções como as incorporações podem ajudar.
1.2 O que é pesquisa semântica e o que pode ser construído com ela?
A principal diferença entre a pesquisa clássica e a pesquisa semântica é usar pequenos vetores para representar itens.
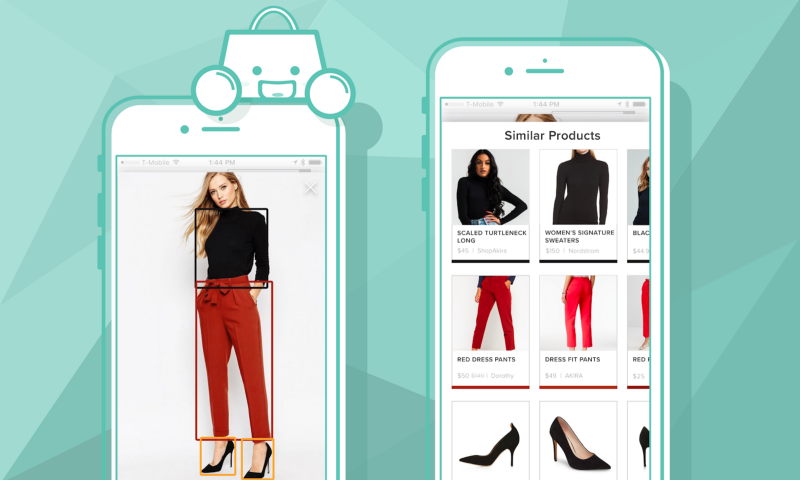
A pesquisa visual pode ser usada para procurar plantas PlantNet, mas também para procurar roupas
O uso de incorporações é poderoso: pode ser usado para criar sistemas que podem ajudar os usuários a encontrar itens de que gostam (música, produto, vídeos, receitas, …) usando muitos tipos de consultas. Ele não pode funcionar apenas em sistemas de pesquisa explícitos (inserindo uma consulta em uma barra de pesquisa), mas também em sistemas implícitos (produtos relevantes em sites de varejistas, notícias personalizadas em editores, postagens interessantes em plataformas sociais).Muitos tipos de sistemas podem ser construídos em cima da pesquisa.
Um sistema de pesquisa de texto leva como entrada uma consulta de texto e retorna resultados: pesquisa de roupas, músicas, notícias
Um sistema de pesquisa visual toma como entrada uma imagem e retorna itens semelhantes em comparação com esta imagem.
Um sistema de recomendação usa como entrada algum contexto, informações do usuário e retorna itens semelhantes que otimizam para um determinado objetivo: recomendar filmes, carros, casas
Redes sociais, redes de publicidade, mecanismos de busca especializados (pesquisa de produtos) usam técnicas de recuperação para fornecer as melhores informações
É possível pesquisar uma variedade de itens, qualquer coisa que tenha imagens, texto, áudio ou esteja disponível em um contexto. Exemplos populares de tais sistemas são a lente do Google, a recomendação da Amazon ou os mais novos para pesquisa de moda, pesquisa de plantas, …Em menor escala, pode ser interessante indexar suas fotos, suas mensagens, encontrar um programa de TV entre muitos, encontrar atores em um programa de TV, …
2. Design geral: como construir pesquisa semântica?
Um sistema de pesquisa semântica é composto por duas partes: um pipeline de codificação que constrói índices e um pipeline de pesquisa que permite ao usuário usar esses índices para pesquisar itens.
3 Pipeline de codificação: de itens a vetores e índices
O primeiro passo para construir um sistema de recuperação semântica é codificar itens em pequenos vetores (centenas de dimensões). Isso é possível para muitos itens e pode ser usado para indexá-los e pesquisar entre eles de forma eficiente.
3.1 Extraia dados relevantes
Os sistemas de recuperação podem codificar itens de muitos aspectos diferentes, por isso é importante pensar no que codificar. Alguns exemplos de itens para codificar são roupas, brinquedos, animais, notícias, músicas, filmes, receitas. Cada um deles tem características diferentes: eles podem ser expressos por como se parecem, como podem ser descritos, como aparecem entre outros itens.Todas essas informações podem ser codificadas como incorporações. Um eixo diferente para pensar é quantos itens codificar? Todos os itens são únicos ou faz mais sentido agrupá-los por características relevantes? Existem alguns itens que são mais relevantes e devem ser uma prioridade? Fazer essa escolha cedo pode ter consequências dramáticas para o resto do sistema.
Este personagem de Star Wars C-3PO pode ser codificado com uma imagem dele, uma descrição, como ele aparece em um gráfico (está em um filme de Star Wars, aparecendo na data desses filmes, …), quão popular ele é, mas também que ele aparece junto com R2-D2 com frequência, e tem uma voz robótica. Todas essas informações podem ser relevantes. Qual escolher pode afetar muito o desempenho do sistema.
Para um sistema de recomendação, as informações de co-ocorrência podem funcionar melhor, mas para um sistema de pesquisa visual, a imagem pode ser a mais relevante.
3.2 Codifique os itens
3.2.1 Conteúdo
Os itens podem ser codificados com base em seu conteúdo. As roupas podem ser bem representadas com imagens. Os sons são identificados por seu conteúdo de áudio. As notícias podem ser entendidas usando seu texto. Os modelos de aprendizagem profunda são muito bons em produzir representações de conteúdo que têm boas propriedades de recuperação.
As imagens podem ser representadas com incorporações (leia uma introdução sobre isso no meu post anterior). Redes como ResNet ou EfficientNet são realmente bons extratores de recursos para imagens, e muitas redes pré-treinadas estão disponíveis.Também não é apenas possível representar toda a imagem, mas também é possível usar segmentação ou detecção de objetos antes de aplicar o codificador de imagem.
A segmentação pode ser usada para extrair parte da imagem pixel por pixel, pode ser relevante para extrair camisas e calças de uma imagem de moda
A detecção é útil para extrair zonas retangulares das imagens
Uma diferença importante nos vários codificadores de imagem é qual perda eles estão usando. As redes convolucionais são frequentemente treinadas usando perda tripla, entropia cruzada ou, mais recentemente, perda contrastiva. Cada perda pode fornecer características diferentes para incorporações: perda tripla e perda contrastiva tentam montar itens semelhantes, enquanto a entropia cruzada reunirá itens da mesma classe. Muitos modelos pré-treinados são treinados na ImageNet com entropia cruzada para classificação de imagens, mas o aprendizado auto-supervisionado (simclr byol) está mudando rapidamente isso para tornar possível o treinamento não supervisionado sem classificação. Em um futuro próximo, os melhores codificadores podem não precisar de dados rotulados. Este tutorial em vídeo do CVPR2020 é muito bom para entrar em detalhes sobre recuperação de imagens.Ser capaz de codificar imagens como vetores torna possível construir muitos aplicativos: qualquer coisa que possa ser vista e assistida é algo que possa ser codificada. Pesquisa visual de moda, pesquisa de plantas, pesquisa de produtos são possíveis. A pesquisa em filmes e outros conteúdos de vídeo também se torna possível.
3.2.1.2 Texto
O texto também pode ser representado com incorporações. O texto pode ter várias formas e comprimentos: palavras, frases, documentos. A aprendizagem profunda moderna agora pode representar a maioria daqueles em representação poderosa.
Word2vec: a codificação de palavras é uma das formas mais populares de incorporação. A partir do contexto das palavras nos documentos, é possível inferir quais palavras estão mais próximas em significado às outras. Word2vec ilustrado e word2vec explicados introduzem bem o conceito e os métodos
Os transformadores são um método mais novo que torna possível codificar frases inteiras, levando melhor em conta as dependências entre muitas palavras nas frases. Alguns anos atrás, eles foram capazes de se tornar o estado da arte em muitas tarefas. O transformador ilustrado é uma introdução interessante a eles.
Arquitetura Bert: finalmente, a arquitetura Bert é um tipo especial de transformador que pode ser bem treinado em um ambiente multitarefa. Foi chamado de momento ImageNet de PNL. bert ilustrado é uma boa introdução a ele.
Na prática, alguns bons codificadores para texto podem ser:
Incorporações de palavras de luvas. Este pequeno exemplo de repositório word-knn que eu construí pode ajudar a começar rapidamente
O modelo labse para incorporações de frases é um modelo bert pré-treinado que pode codificar incorporações de até 109 idiomas em um único espaço
As incorporações de documentos podem ser representadas como a média das frases.
Ser capaz de codificar texto como vetores torna possível pesquisar artigos, descrição de filmes, títulos de livros, parágrafos da Wikipédia, … Muito conteúdo está disponível como texto, portanto, usar essas informações para um sistema de recuperação pode ser um dos primeiros passos a tentar.
3.2.1.3 E todos os outros conteúdos
Além do texto e da imagem, o conteúdo de áudio também pode ser codificado como incorporações (pense em aplicativos como o Shazam).Exemplos de Jina e vectorhub fornecem muitos bons exemplos de como codificar incorporações usando conteúdo
3.2.1.4 Escalando
Para codificar não apenas algumas centenas, mas bilhões de incorporações, trabalhos de lote como spark ou Pyspark podem ser realmente úteis. A maioria dos modelos de imagem e texto será capaz de codificar milhares de amostras por segundo. Codificar um bilhão de amostras em uma hora exigiria cerca de 300 executores.
A codificação de itens por seu conteúdo funciona bem e escala para bilhões de itens. Mas o conteúdo não é o único dado disponível, vamos ver como os outros itens podem ser codificados.
3.2.2 Distribuição: tendências
Itens como roupas, filmes e notícias geralmente estão presentes em sites visitados por muitos usuários. Os usuários interagem com os itens, gostam ou não, alguns itens são populares, alguns itens são vistos apenas por partes dos usuários e itens relacionados geralmente são vistos juntos. Tudo isso são dados de interação. Esses dados de interação podem ser usados para codificar itens. Isso é particularmente útil para definir incorporações para as quais a métrica de distância é baseada em como as pessoas interagem com esses itens sem precisar de nenhuma informação sobre seu conteúdo.
3.2.2.1 SVD
Um primeiro método para construir essa incorporação de comportamento é SVD: decomposição de valor singular.
No contexto em que para um conjunto de itens (notícias, produtos, restaurantes,…) classificações de usuários estão disponíveis, é possível calcular incorporações de usuários e itens. O primeiro passo é calcular uma matriz de similaridade de item de usuário e usando fatoração de matriz (SVD), incorporações de usuário e incorporações de itens são computadas. O svd de item de usuário é uma introdução simples a esse processo.
Outra configuração aparece quando é possível observar co-ocorrências entre itens. Um exemplo poderia ser produtos (roupas, casas, laptops, …) que são visualizados ou comprados juntos por um usuário. Essas co-ocorrências podem ser expressas com seu PMI e essa matriz item-item pode ser fatorada com SVD em incorporações de itens. Essas duas postagens de blog fornecem uma boa introdução.
Essa maneira de codificar itens em incorporações é particularmente poderosa para codificar as preferências e o comportamento do usuário em relação aos itens sem precisar de nenhum conhecimento sobre esses itens. Isso significa que ele pode funcionar em todos os idiomas e para itens onde nenhum conteúdo está disponível.
3.2.2.2 Incorporação de gráficos
Uma segunda maneira de codificar itens usando sua distribuição é a incorporação de gráficos.
Muitos conjuntos de dados podem ser representados como gráficos. Um bom exemplo é um gráfico de conhecimento. Wikidata e DBpedia, por exemplo, representam o conhecimento no mundo real como entidades como pessoas, empresas, países, filmes… e relações entre eles, como cônjuge, presidente, nacionalidade, ator.
Wikidata representa o conhecimento sobre as entidades mundiais
Isso forma um gráfico: entidades são nós no gráfico, e esses nós são ligados por arestas que são relações.
Existem muitos algoritmos interessantes e artigos recentes sobre incorporações de gráficos e redes neurais de gráficos em geral (este canal de telegrama é ótimo para seguir o tópico), mas um simples e escalável é o Pytorch Big Graph. Este ajudante que construí com um colega pode ajudar a construir grandes conjuntos de dados gráficos para PBG e visualizar alguns resultados knn.
Essa representação de dados como um gráfico pode ser usada para construir incorporações para nós e transformação para arestas que possibilitam ir de um nó para o outro. A ideia é aprender a mapear um nó para outro nó usando ambas as incorporações de nós e uma transformação que pode ser aprendida para a borda. Tal transformação pode ser uma tradução. Isso dá resultados surpreendentemente bons para prever a próxima vantagem.
O PBG possibilita aprender a transformação entre bilhões de incorporações
A contribuição do Pytorch Big Graph é particionar os nós e arestas para que seja possível aplicar esse aprendizado a centenas de milhões de nós e bilhões de arestas.
Os gráficos são muito versáteis e podem não apenas representar gráficos de conhecimento, mas também links entre usuários, produtos, restaurantes, filmes, … Usar incorporações de gráficos pode ser uma boa maneira de usar a distribuição de itens para codificá-los.
3.2.3 Composição e multimodal
Agora temos incorporações de itens de várias perspectivas, e eles podem oferecer informações complementares. Como uma peça de roupa se parece, como os usuários interagem com ela e como ela é descrita podem ser relevantes.
Como essas incorporações podem ser combinadas em uma única?
Concatenação: concatenar as incorporações é um método básico que funciona surpreendentemente bem. Por exemplo, a concatenação de incorporações de texto e imagem torna possível pesquisar um item usando seu texto, sua imagem ou ambos.
Modelo multimodal: a aprendizagem profunda da visão e da linguagem está se tornando muito popular, e muitos modelos (imagebert, vilbert, uniter, vl-bert, veja esta demonstração interessante) propõem aprender com a linguagem e o texto, para produzir representações de modelos cruzados.
Ajustando uma rede para uma tarefa específica usando várias incorporações
A composição é uma ferramenta poderosa e pode ser usada para ter uma visão completa dos itens a serem codificados.
3.2.4 Popularidade
Um tópico importante a ser considerado nos sistemas de recuperação e recomendação é a popularidade dos itens. Mostrar itens impopulares geralmente resulta em resultados não relevantes.
Uma maneira simples de resolver esse problema é adicionar um termo de popularidade à incorporação. Por exemplo, o último componente pode ser o inverso do registro do número de visualizações desse item. Dessa forma, a distância L2 entre uma consulta com um 0 no componente de popularidade classificará em primeiro lugar os itens mais populares. Isso pode ajudar a remover alguns dos itens impopulares dos principais resultados, mas isso não é perfeito, pois o trade-off entre semelhança e popularidade deve ser definido manualmente.
Treinar as incorporações para um objetivo específico é uma maneira melhor de resolver isso.
3.2.5 Treinamento
Para codificar itens, modelos de conteúdo pré-treinados e métodos baseados em distribuição funcionam bem, mas para ajustar as incorporações para uma determinada tarefa, a melhor maneira é treinar um novo modelo para isso.
Muitas tarefas podem ser consideradas para treinar incorporações: baseadas em conteúdo, baseadas em distribuição e para objetivos mais específicos, como engajamento, cliques ou talvez até mesmo felicidade do usuário.
3.2.5.1 Treinamento específico de imagem
As incorporações de imagens podem ser treinadas com tarefas como classificação, identificação, segmentação. Groknet é um bom exemplo de um grande sistema para aprender incorporações de imagens com objetivos específicos… Ele aprende em muitos conjuntos de dados díspares para muitas tarefas diferentes.
Groknet: usando um tronco de visão para treinar incorporações com muitos tipos de conjuntos de dados e perdas.
FaceNet é outra maneira simples de treinar incorporações de imagens além da classificação. A perda tripla permite que ele aprenda um tipo específico de incorporação de imagem: incorporação de rosto. Isso pode ser reutilizado para outros exemplos, como incorporação de ursos de treinamento
3.2.5.2 Treinamento específico do texto
Bert é um ótimo exemplo de um modelo que pode ser ajustado e reutilizado para vários objetivos. Em particular, a biblioteca de transformadores huggingface e a biblioteca de transformadores thesentence com base nela são ótimas para ajustar um modelo de texto para um caso de uso específico. Centenas de arquiteturas de transformadores diferentes estão disponíveis lá com dezenas de configurações de treinamento.
3.2.5.3 Distribuição: treinamento específico de recomendação
Incorporações de ajuste fino para recomendação
Outra configuração é um modelo de treinamento para recomendação. Isso pode funcionar muito bem para ir além do SVD e treinar incorporações de produtos e usuários. A biblioteca criteodeepr com seu blog que o acompanha é uma boa introdução a este tópico. Os recomendadores do Tensorflow são outro bom ponto de entrada.
3.2.5.1 E muito mais
Além dessas configurações de treinamento específicas, as incorporações de treinamento são o núcleo da aprendizagem profunda e da aprendizagem de representação. Pode ser aplicado em muitos ambientes e para muitos objetivos. Alguns exemplos interessantes são:
StarSpace, um projeto do Facebook para aprender incorporações de imagens, texto, gráfico e distribuição para vários objetivos
Incorporação de receitas um exemplo de um projeto para aprender incorporações de receitas a partir de ingredientes, instruções e imagens
Para se aprofundar mais neste tópico de treinamento de redes neurais para recuperação de informações, esses slides do ecir2018 estão bastante completos.
3.3 Construa índices relevantes
Uma vez que as incorporações são construídas, precisamos de uma maneira de olhar entre elas rapidamente. Isso pode ser alcançado graças ao algoritmo k do vizinho mais próximo. A versão simples consiste em calcular uma distância entre um vetor e todos os vetores do conjunto de dados. Isso pode ser melhorado muito usando algoritmos aproximados de k vizinhos mais próximos.
Usando a implementação correta dos índices knn, é possível procurar os vizinhos mais próximos de uma incorporação a partir de um conjunto de bilhões de vetores em milissegundos. Graças às técnicas de quantização, isso pode caber em apenas alguns GB de memória.
3.3.1 O que indexar, quantos índices?
Em termos de desempenho, as coisas importantes a serem otimizadas ao construir índices são:
Latência: quanto tempo leva para um índice retornar resultados?
Lembre-se: quantos dos resultados de um knn de força bruta são encontrados no resultado do índice?
Memória: quão grande é o índice, quanta memória é necessária para mantê-lo na ram?
Em termos de relevância de pesquisa, pode ser importante particionar as incorporações nas dimensões certas. Por exemplo, os itens podem ser particionados por categorias amplas (calças, camisetas,…) para um aplicativo de pesquisa visual de moda. Esse particionamento pode ter consequências ao construir os índices, por isso é melhor decidir cedo.
3.3.2 Aproximado knn e bibliotecas
Para escolher a melhor maneira de construir índices, o número de incorporações é um bom discriminador.
Alguns exemplos de algoritmos apropriados podem ser:
Para menos de mil incorporações, uma busca de força bruta faz sentido
Por menos de um milhão, um algoritmo rápido, mas não eficiente em termos de memória (como HNSW) é apropriado
Por menos de um bilhão, a quantização (usando k-means e fertilização in vitro) se torna importante
Para um exemplo trilhão, a única solução são os índices em disco
Alguns algoritmos para calcular knn aproximado são:
Um knn ingênuo: que pode ser implementado em O(nlog(k)) com uma fila de prioridade ou O(n) com quickselect ou introselect. Para poder calcular isso, é necessário armazenar todas as incorporações na memória.
HNSW: um algoritmo que constrói um gráfico de vizinhos. É O(log(N)) na pesquisa, mas não é exato. Leva cerca de duas vezes a memória das incorporações porque precisa armazenar o gráfico
FIV: o algoritmo de arquivo invertido consiste em dividir o espaço de incorporação em várias partes e usar k-means para encontrar uma aproximação de incorporação. É menos rápido que o HNSW, mas permite diminuir a memória exigida pelo índice tanto quanto necessário.
Para saber mais sobre todos os tipos de índices, recomendo ler esta página da documentação do faiss. Este tutorial do CVPR2020 se aprofunda sobre esses algoritmos, aconselho assisti-lo se você estiver interessado em entender os detalhes mais finos.
As bibliotecas que implementam esses índices incluem:
Faiss Uma biblioteca muito ampla que implementa muitos algoritmos e interfaces limpas para construí-los e pesquisar a partir deles
Hnswlib é atualmente a implementação mais rápida de HNSW. Altamente especializado e otimizado
Annoy é outro algoritmo knn, implementado pelo Spotify
Como o knn aproximado está no centro da recuperação moderna, é um campo de pesquisa ativo. Notavelmente, esses artigos recentes introduzem novos métodos que superam algumas métricas.
Scann do Google é um novo método que é de última geração, superando HNSW em velocidade e recall usando quantização anisotrópica
Catalisador do Facebook que propõe treinar o quantizador com uma rede neural para uma tarefa específica
Eu aconselho começar pelo faiss por sua flexibilidade e tentar outras bibliotecas para necessidades específicas.
3.3.3 Escala
Para ser capaz de escalar para muitas incorporações, as técnicas principais são:
Quantificação: as incorporações podem ser compactadas em índices de tamanho 1/100 e mais
Sharding: particionar os itens ao longo de uma dimensão, torna possível armazenar os índices em diferentes máquinas
Para escalar em termos de velocidade, a velocidade do índice é realmente importante (algoritmos como HNSW podem ajudar muito), mas servir também é crucial. Mais detalhes sobre isso na seção de serviço.
Em termos práticos, é possível construir um índice de 200 milhões de incorporações com apenas 15 GB de memória RAM e latências em milissegundos. Isso desbloqueia sistemas de recuperação baratos na escala de um único servidor. Isso também significa que, na escala de alguns milhões de incorporações, os índices knn podem caber em apenas centenas de megabytes de memória, que podem caber em máquinas de mesa e até mesmo dispositivos móveis.
3.3.4 Índices Knn como um componente de banco de dados
Bancos de dados existem em todos os tipos: bancos de dados relacionais, armazenamentos de chaves/valores, bancos de dados de gráficos, armazenamentos de documentos,… Cada tipo tem muitas implementações. Esses bancos de dados trazem maneiras convenientes e eficientes de armazenar informações e analisamos-las. A maioria desses bancos de dados fornece maneiras de adicionar novas informações e consultá-las pela rede e usar APIs em muitos idiomas. Esses bancos de dados em seu núcleo estão usando índices para torná-los rápidos para consultá-los. Os bancos de dados relacionais em seu núcleo usam mecanismos de armazenamento (como o InnoDB) que usam índices adaptados. As lojas de chaves/valor implementam índices baseados em hash compartilhados e distribuídos.
E se os índices knn pudessem ser integrados às implementações de banco de dados como apenas mais um tipo de índice?
Isso é o que é proposto por projetos como
Uma integração de pesquisa elástica de HNSW: eles propõem adicionar hnsw como parte do banco de dados geral de pesquisa elástica. Isso torna possível combinar a pesquisa knn com consultas rigorosas, consultas de texto e junções fornecidas pela pesquisa elástica
Unicorn, um sistema privado do Facebook que permite integrar a pesquisa knn em um banco de dados de gráficos. Como consequência, as consultas nesse gráfico podem ter partes usando consultas knn.
Além desses sistemas específicos, o que eu acho realmente interessante nesse conceito é a ênfase em tornar a construção de índices knn um processo simples que pode ser acionado facilmente:
A adição de novos dados aciona automaticamente a reindexação ou a adição direta de incorporações aos índices existentes
Escolhendo automaticamente o tipo certo de índice knn com base na restrição específica do sistema
4. Pipeline de pesquisa: de índices a sistemas de pesquisa semântica
O pipeline de pesquisa é a parte do sistema que geralmente é executada em uma configuração on-line e de baixa latência. Seu objetivo é recuperar resultados relevantes para uma determinada consulta. É importante que ele retorne resultados em segundos ou milissegundos, dependendo das restrições e para ocupar baixas quantidades de memória.
É composto por uma maneira de extrair dados relevantes de uma consulta, um codificador para transformar esses dados em incorporações, um sistema de pesquisa que usa índices construídos no pipeline de codificação e, finalmente, um sistema de pós-filtragem que selecionará os melhores resultados.
Ele pode ser executado em servidores, mas para uma quantidade menor de itens (milhões), também pode ser executado diretamente no lado do cliente (navegadores e dispositivos pequenos).
4.1 Extraia partes de consultas
A primeira parte do sistema consiste em pegar uma consulta como entrada e extrair dados relevantes dela para poder codificá-la como incorporações de consulta.
Alguns exemplos interessantes de consultas incluem procurar roupas semelhantes, procurar uma planta de uma foto, procurar músicas semelhantes de um registro de áudio. Outro exemplo pode ser uma lista de itens vistos pelos usuários.
A consulta pode assumir qualquer forma: uma imagem, texto, uma sequência de itens, áudio, …
Para poder codifico-lo da melhor maneira, várias técnicas podem ser usadas:
Para uma segmentação de imagem ou detecção de objetos pode ser relevante: extrair apenas roupas da foto de uma pessoa, por exemplo
Para texto, pode ser relevante extrair entidades nomeadas da consulta, pode fazer sentido aplicar a extensão de consulta para adicionar termos relevantes ou corrigir erros de digitação
Para uma lista de itens, agrupar os itens para selecionar apenas um subconjunto relevante pode ajudar
Segmentação de pessoas para extrair roupas
4.2 Codifique a consulta
Depois que os dados relevantes são extraídos da consulta, cada um desses elementos pode ser codificado. A maneira de codificá-lo geralmente é semelhante à maneira como as incorporações dos índices são construídas, mas é possível aplicar técnicas que são relevantes apenas para a consulta.
Por exemplo:
Uma média de vários elementos para obter resultados relevantes para uma lista de itens
Agrapee os pontos da consulta e escolha um cluster como a consulta
Use modelos mais complexos para gerar consultas apropriadas no mesmo espaço, usando modelos de transformador para resposta a perguntas (veja DPR), ou transformações de incorporações de gráficos (veja PBG), por exemplo
Para o caso de uso de recomendação, é possível treinar diretamente um modelo que produzirá as melhores consultas para um determinado objetivo, veja este post do blog do criteo como exemplo.
4.3 Pesquise os índices certos
Dependendo do tipo de consulta, pode ser relevante construir não apenas um índice, mas vários. Por exemplo, se a consulta tiver uma parte de filtro para uma determinada categoria de item, pode fazer sentido construir um índice específico para esse subconjunto de incorporações.
Aqui, selecionar o índice da Toyota tornou possível devolver apenas produtos relevantes desta marca.
4.4 Filtragem de postagens
Construir vários índices é uma maneira de introduzir filtragem rigorosa em um sistema, mas outra maneira é fazer uma grande consulta knn e pós-filtrar os resultados.
Isso pode ser relevante para evitar a construção de muitos índices
4.5 Porção
Finalmente, a construção de um aplicativo de serviço torna possível expor os recursos aos usuários ou outros sistemas. Graças às bibliotecas rápidas de k vizinhos mais próximos, é possível ter latências em milissegundos e milhares de consultas por segundo.
Há muitas opções para construir isso. Dependendo do estado e do escopo dos projetos, diferentes tecnologias fazem sentido:
Para experimentar inicialmente, a construção de um aplicativo de frasco simples com faiss pode ser feita em apenas 20 linhas de código
Usar um servidor adequado com frasco como gunicorn com gevent pode ser suficiente para atingir latências de milissegundos a milhares de qps
Para obter ainda mais desempenho, a construção de um serviço de serviço com linguagens nativas como ferrugem ou C++ pode ser feita. O benefício de usar uma linguagem nativa para esse tipo de aplicativo pode ser evitar custos de GC, já que o próprio índice knn é construído em C++, apenas o código de serviço precisa ser otimizado.
As bibliotecas Aknn são mais frequentemente construídas em c++, mas as ligações podem ser feitas com muitas linguagens (java, python, c#) manualmente ou com swig. Para integração com um aplicativo existente, isso pode ser o mais relevante em alguns casos.
4.6 Avaliação
A avaliação de um sistema de pesquisa semântica dependerá muito do caso de uso real: um sistema de recomendação ou um sistema de recuperação de informações pode ter métricas muito diferentes. As métricas podem ser amplamente divididas em duas categorias: métricas on-line e métricas off-line. As métricas on-line podem ser medidas apenas a partir do uso do sistema, muitas vezes em uma configuração de teste A/B. Para recomendação, em particular, a taxa de cliques ou diretamente a receita pode ser considerada, este documento explica alguns deles com mais detalhes. As métricas off-line podem ser calculadas a partir de conjuntos de dados off-line e exigem alguns rótulos. Esses rótulos podem ser implícitos com base em como os usuários interagem com o sistema (o usuário clicou nesse resultado?) ou explícitos (annotadores que fornecem rótulos). Algumas métricas off-line são gerais para todos os sistemas de recuperação, a página da Wikipedia sobre isso é bastante completa. As métricas frequentemente usadas incluem o recall, que mede o número de documentos relevantes que são recuperados, e o ganho cumulativo descontado que explica a classificação dos itens recuperados.
Antes de fazer análise quantitativa, construir uma ferramenta de visualização e analisar o resultado geralmente fornece insights úteis.
5. Soluções práticas para construir isso facilmente
5.1 Soluções de código aberto de ponta a ponta
Outra maneira de começar a criar aplicativos de pesquisa semântica é usar soluções de código aberto pré-existentes. Recentemente, várias organizações e pessoas os construíram. Eles variam em objetivos, alguns deles são específicos para uma modalidade, alguns deles lidam apenas com a parte knn e alguns tentam implementar tudo em um sistema de pesquisa semântica. Vamos anuná-los.
Jina é um projeto de código aberto de pesquisa semântica de ponta a ponta construído pela empresa de mesmo nome. Não é um único serviço, mas fornece boas APIs em python para definir como criar codificadores e indexadores, e um sistema de configuração YAML para definir fluxos de codificação e pesquisa. Ele propõe encapsular cada parte do sistema em contêineres docker. Dezenas de codificadores já estão disponíveis, e vários indexadores também são construídos em seu sistema. Ele também fornece tutoriais e exemplos sobre como construir sistemas de pesquisa semântica específicos.
Eu recomendo ler o grande post do blog da jina. Sua sintaxe e flexibilidade é o que o torna o mais interessante e poderoso.
Milvus é um serviço de pesquisa semântica focado na indexação, usando faiss e nmslib. Ele fornece recursos como filtragem e adição de novos itens em tempo real. A parte de codificação é deixada principalmente para os usuários fornecerem. Ao integrar várias bibliotecas aknn, ele tenta ser eficiente.
A pesquisa elástica é um banco de dados de indexação clássico, frequentemente usado para indexar categorias e texto. Agora tem uma integração hnsw que fornece indexação automática e uso de todos os outros índices estritos de pesquisa elástica. Se as latências em segundos forem aceitáveis, esta pode ser uma boa escolha.
O Vectorhub fornece muitos codificadores (imagem, áudio, texto, …) e um módulo python fácil de usar para recuperá-los. Tem uma rica documentação sobre a construção de sistemas semânticos e este pode ser um bom ponto de partida para explorar codificadores e aprender mais sobre sistemas semânticos.
Haystack é um sistema de ponta a ponta para resposta a perguntas que usa knn para indexação semântica de parágrafos. Ele se integra a muitos modelos de texto (transformadores de rosto abraço, DPR, …) e vários indexadores para fornecer um pipeline de resposta a perguntas completo e flexível. Isso pode servir como um bom exemplo de um sistema de pesquisa semântica específico de modalidade (rendrondo a perguntas de texto).
Esses projetos são ótimos para começar neste tópico, mas todos eles têm desvantagens. Pode ser em termos de escalabilidade, flexibilidade ou escolha de tecnologia. Para ir além da exploração e pequenos projetos e construir projetos de maior escala ou personalizados, muitas vezes é útil criar sistemas personalizados usando os blocos de construção mencionados aqui.
5.2 Do zero
Escrever um sistema de pesquisa semântica pode parecer uma tarefa enorme devido a todas as diferentes partes que são necessárias. Na prática, a versatilidade e a facilidade de uso das bibliotecas para codificação e indexação tornam possível criar um sistema de ponta a ponta em algumas linhas de código. O repositório de incorporação de imagens que eu construí pode ser uma maneira simples de começar a construir um sistema do zero. Você também pode verificar a pequena palavra knn que eu construí como um exemplo simples. O ajudante PBG que construí com um colega também pode ajudar a inicializar o uso de incorporações de gráficos. Este vídeo do CVPR2020 é outro bom tutorial para começar com isso.
De todos os componentes que apresentei neste post, muitos são opcionais: um sistema simples só precisa de um codificador, um indexador e um serviço de serviço simples.
Escrever um sistema do zero pode ser útil para aprender sobre ele, para experimentação, mas também para integrar tal sistema em um ambiente de produção existente. Segmentar a nuvem pode ser uma boa opção, veja este tutorial do google cloud. Também é possível construir esse tipo de sistema em qualquer tipo de sistema de produção.
6. Conclusão
6.1 Além da pesquisa: aprendizado de representação
Além da construção de sistemas de pesquisa semântica, sistemas de recuperação e incorporações fazem parte do campo mais amplo do aprendizado de representação. O aprendizado de representação é uma nova maneira de construir software, às vezes chamado de software 2.0. As incorporações são as partes centrais das redes neurais profundas: elas representam dados como vetores em muitas camadas para eventualmente prever novas informações.
O aprendizado de representação fornece incorporações para recuperação e pesquisa semântica, mas, em alguns casos, a recuperação também pode ajudar no aprendizado de representação:
Usando a recuperação como parte do treinamento: em vez de pré-gerar exemplos negativos (para um sistema que usa uma perda tripla, por exemplo), um sistema de recuperação pode ser usado diretamente no treinamento (isso pode ser feito, por exemplo, com a integração entre faiss e PyTorch)
Usando a recuperação como uma maneira de criar conjuntos de dados: exemplos semelhantes podem ser recuperados como parte de um pipeline de aumento de dados
6.2 O que vem a seguir?
Como vimos neste post, os sistemas de recuperação são fáceis de construir e realmente poderosos, encorajo você a brincar com eles e pensar em como eles poderiam ser usados para muitos aplicativos e ambientes.
A busca e recuperação semântica são áreas de pesquisa ativas e muitas coisas novas aparecerão nos próximos anos:
Novos codificadores: o conteúdo 3D está sendo desenvolvido rapidamente, tanto com bibliotecas como PyTorch 3d quanto com artigos impressionantes como PIFuHD
A quantificação e a indexação também estão melhorando rapidamente com artigos como Scann e Catalyzer
O treinamento de ponta a ponta e a representação multimodal estão progredindo rapidamente com a visão e a linguagem tendo muito progresso: em direção a uma maneira generalizada de construir qualquer representação?
Onde os sistemas de recuperação podem viver? Até agora, eles eram principalmente localizados em servidores, mas com o progresso do aknn e da quantização, quais aplicativos eles podem desbloquear nos dispositivos do usuário?
Os sistemas de pesquisa semântica também estão progredindo rapidamente: centenas de empresas estão construindo-os, e vários bons sistemas de código aberto estão começando a surgir