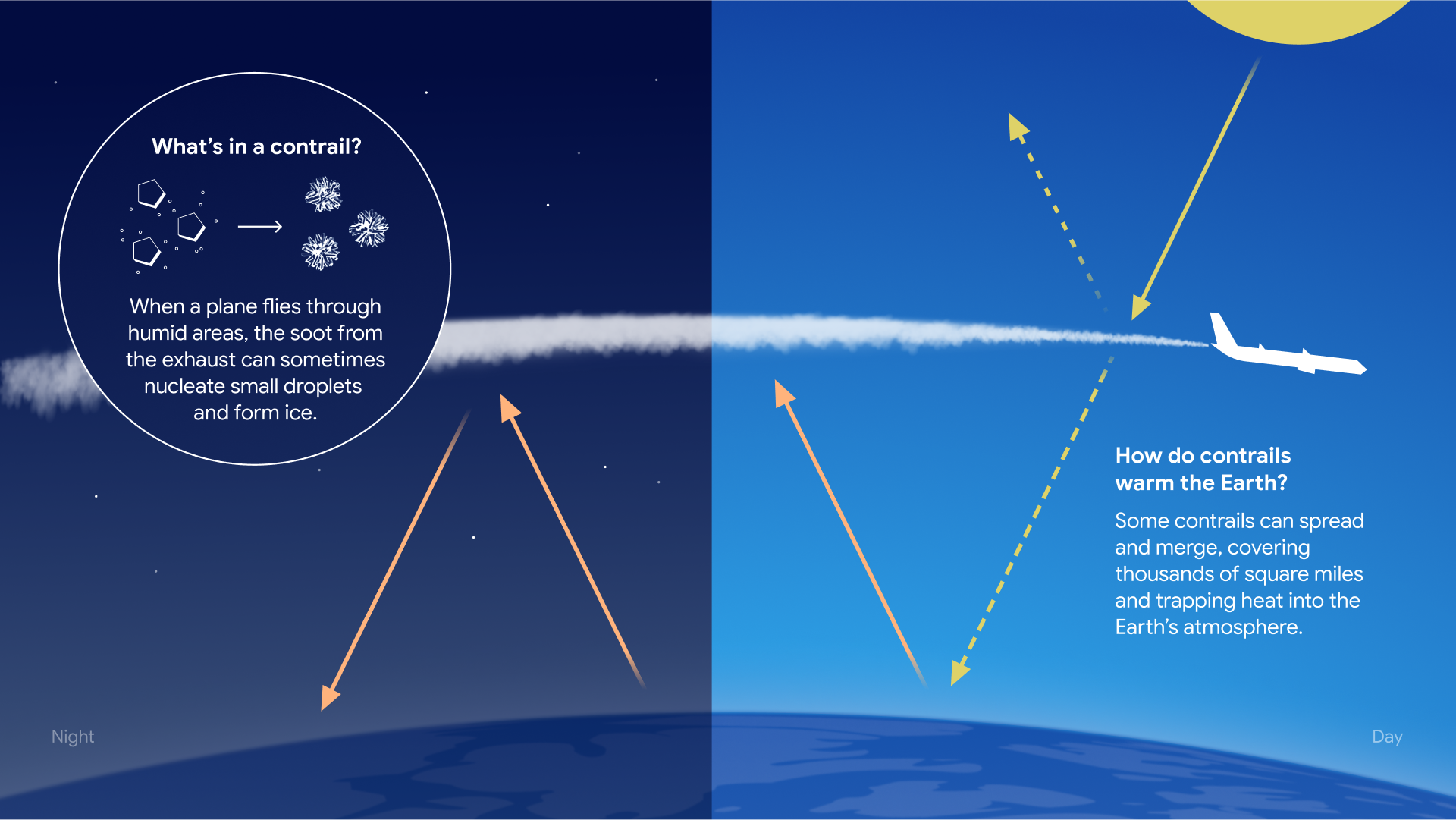
Rastros, abreviação de trilhas de condensação, são nuvens em forma de linha que às vezes você vê atrás dos aviões. Eles se formam quando o vapor d’água no ar se condensa em torno de pequenas partículas de fuligem e outros poluentes emitidos pelos motores dos aviões.
Como os rastros contribuem para o aquecimento global?
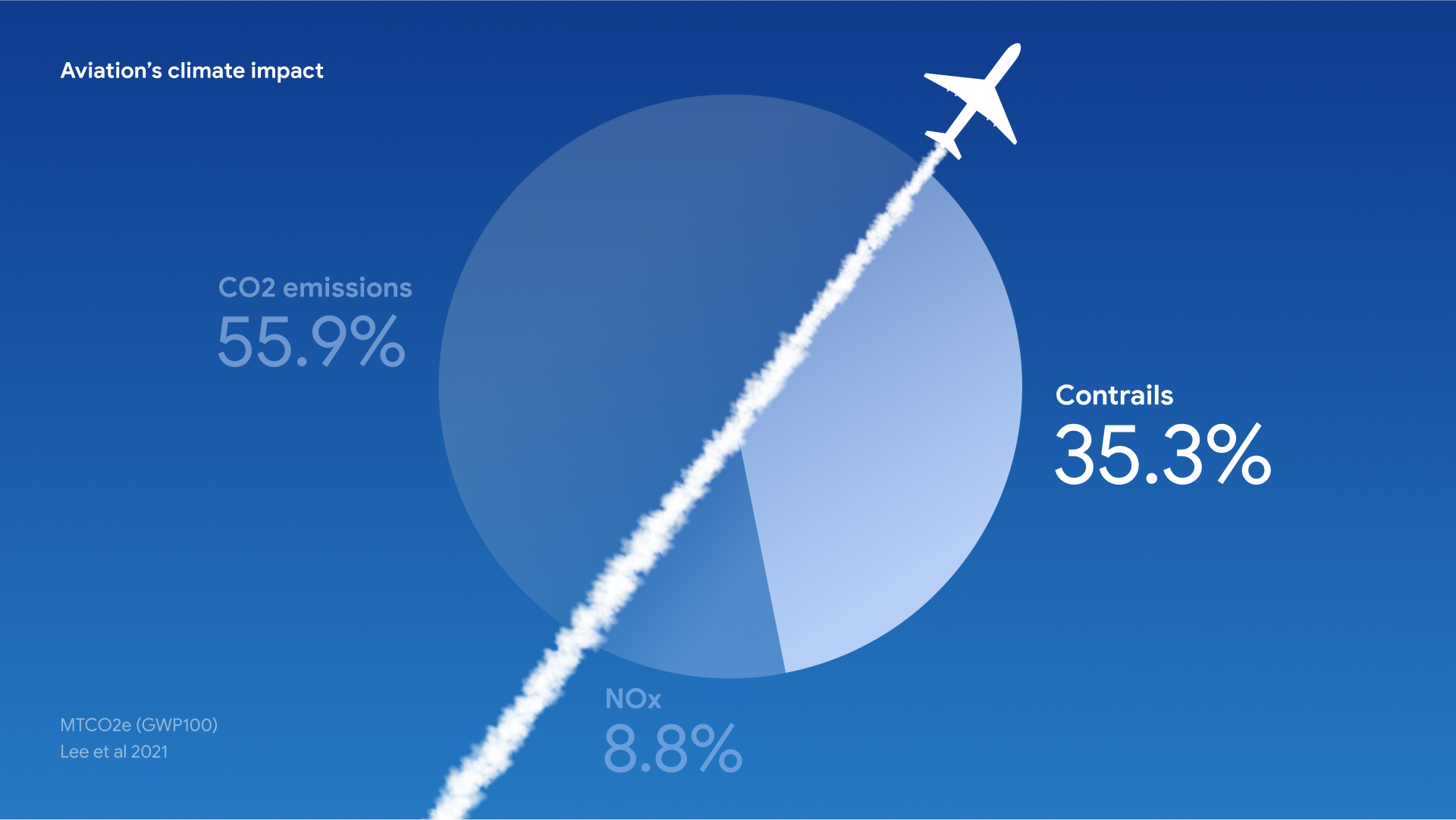
Os rastros podem persistir como nuvens cirros por minutos ou horas, dependendo das condições. Normalmente, o lado da Terra que não está voltado para o sol libera calor durante a noite. À noite, nuvens naturais e rastros de companhias aéreas retêm o calor. Durante o dia, eles também refletem a luz solar e o calor que entram. Os rastos noturnos aquecem mais do que os diurnos porque não refletem a luz solar que entra e apenas retêm o calor, criando um efeito de aquecimento líquido. Um relatório recente do IPCC observou que as nuvens criadas por rastos são responsáveis por cerca de 35% do impacto do aquecimento global da aviação.
Usando a IA do Google para ajudar as companhias aéreas a evitar rastros
Os aviões nem sempre fazem rastros. Os rastros só ocorrem quando os aviões voam por regiões úmidas. Se os aviões evitarem intencionalmente voar através destas regiões, poderão evitar a criação de rastos de aquecimento, com impacto mínimo no consumo de combustível.
O desafio é saber onde essas regiões irão ocorrer. Ao combinar enormes quantidades de dados meteorológicos, dados de satélite e dados de voo, a IA pode criar previsões de última geração sobre quando e onde é provável que se formem rastos. Pilotos e despachantes podem então usar essas informações para ajustar as altitudes de seus voos.
Nossa equipe desenvolveu uma abordagem para aproveitar imagens de satélite e visão computacional para detectar rastros e atribuí-los a voos associados, com base em centenas de horas de rotulagem de dezenas de milhares de imagens de satélite. A imagem abaixo mostra nossa IA detectando rastros sobre os Estados Unidos, com base em imagens de satélite.
Testando com a American Airlines e Emirates
Um grupo de pilotos da American Airlines e da Emirates realizou 70 voos de teste durante seis meses usando nossas previsões baseadas em IA para evitar rotas que criassem rastros. Após esses voos de teste, analisamos imagens de satélite e descobrimos que as previsões reduziram os rastros em 54% em comparação com quando os pilotos não usaram nossas previsões. Vimos também que os voos que evitavam os rastos queimavam 2% mais combustível, o que se traduziria em 0,3% mais combustível quando dimensionados para toda a frota de uma companhia aérea. (Isso ocorre porque nem todos os voos fazem rastros e, com as previsões da IA, apenas uma fração dos voos precisa ser ajustada.) Juntos, isso sugere que os custos para evitar rastros poderiam estar na faixa de US$ 5-25/tonelada de CO2e, o que tornaria uma das soluções climáticas mais econômicas.
O Fórum Económico Mundial é a organização internacional empenhada em melhorar a situação do mundo através da cooperação público-privada no espírito da cidadania global. Ela se envolve com líderes empresariais, políticos, acadêmicos e outros líderes da sociedade para moldar agendas globais, regionais e industriais
Embora as partes interessadas estejam cada vez mais convencidas de que o turismo sustentável é benéfico e necessário para um setor do turismo robusto e resiliente, quantificar os benefícios a longo prazo para os destinos e as empresas continua a ser um desafio fundamental. Como podem as mais recentes inovações ser aproveitadas para expandir o valor económico da aviação e do turismo e, ao mesmo tempo, atingir a meta líquida zero até 2050? Palestrantes: Rohan Ramakrishnan, João Ricardo Mendes, Sally Davey, Keith Tan, Silvia Garrigo.
O representante do Brasil João Ricardo Mendes no painel desenvolveu a tese de usar correntes de vento a favor, falando que nào acreditava em gás Hélio para aviação.
Como funciona?
Dados rotulados: Nossa equipe de engenheiros analisou imagens de satélite e passou centenas de horas rotulando dezenas de milhares de imagens de rastros coletadas pelo satélite geoestacionário GOES-16.
Treinar um modelo de visão computacional de última geração: Usamos dados rotulados para treinar um modelo de visão computacional de última geração para detectar rastros quando eles são formados. O modelo de detecção pode identificar rastros visíveis nas imagens GOES em questão de 30 minutos.
Combine grandes conjuntos de dados: combinamos nosso modelo de visão computacional com dados meteorológicos em grande escala, dados de voo e imagens de satélite para desenvolver um modelo de previsão mais preciso.
Integrar insights de IA ao fluxo de trabalho dos pilotos: Fizemos uma parceria com a American Airlines para integrar previsões de zonas prováveis de rastros nos tablets que seus pilotos usavam em voo, para que pudessem fazer ajustes de altitude em tempo real, assim como fazem para evitar turbulência, para evitar a criação de rastos.
Analisar resultados de desempenho: Avaliamos o desempenho do modelo de previsão usando imagens de satélite, comparando o número de rastos produzidos em voos onde os pilotos usaram previsões para evitar rastos com rastos criados em voos onde os pilotos não usaram previsões de rastos. Em nossa primeira prova com a American Airlines, observamos uma redução de 54%.
No futuro, estenderemos os nossos modelos a satélites geoestacionários na Europa, África, Oceano Índico ( Meteosat Terceira Geração ), Leste Asiático e Austrália Ocidental ( Hikawari ).
João Ricardo Mendes é um empreendedor brasileiro, conhecido por ser um dos fundadores do Hurb (anteriormente conhecido como Hotel Urbano), uma das maiores agências de viagens on-line do Brasil.
O perfil de João Ricardo Mendes é marcado por sua visão inovadora, espírito empreendedor e compromisso com a responsabilidade social.
João Ricardo Mendes, juntamente com seu irmão José Eduardo Mendes, fundou o Hurb em 2011. A empresa rapidamente ganhou destaque no mercado de turismo brasileiro, oferecendo uma plataforma inovadora que facilita o acesso a hospedagens e pacotes de viagem a preços acessíveis. Sob sua liderança, o Hurb se expandiu significativamente, atendendo milhões de clientes em todo o Brasil e internacionalmente.
Ao longo de sua carreira, João Ricardo Mendes demonstrou um compromisso consistente com a responsabilidade social e as boas ações. Abaixo estão alguns exemplos de suas iniciativas:
Ele acredita na importância de promover práticas que não apenas beneficiem os viajantes e a indústria do turismo, mas também protejam o meio ambiente e promovam o bem-estar das comunidades locais.
João Ricardo Mendes faz parte do World Economic Forum e defende causas importantes (um outro pequeno resumo no Notion com exemplos que estamos planejando nessa colaboração com o WEF para um turismo mais sustentável no Brasil). Nele, você consegue ver que a visualização é o coração de muitas iniciativas.
Incentivo ao Empreendedorismo
Como um empreendedor de sucesso, Mendes tem incentivado o empreendedorismo no Brasil, oferecendo mentorias e apoio a jovens empreendedores e startups.
Ações de Solidariedade
Durante a pandemia de COVID-19, Mendes e o Hurb demonstraram solidariedade, realizando doações e contribuindo para iniciativas de apoio a profissionais de saúde e comunidades afetadas pela crise.
Desafio em Barkeley após desastre em Teresópolis
Investimento em Educação
Não fazemos contratos obrigando o funcionário a permanecer após o período de estudos. Por que?
“O CFO pergunta ao CEO: “O que acontece se investirmos no desenvolvimento dos nossos colaboradores e eles nos abandonarem?”
E o CEO responde: “O que acontece se não o fizermos e eles ficarem?”
Acreditando no poder da educação, João Ricardo Mendes tem investido em iniciativas educacionais, proporcionando oportunidades de aprendizado e desenvolvimento para jovens e adultos.
João Ricardo Mendes é um exemplo de empreendedor que combina sucesso nos negócios com um compromisso genuíno com a sociedade e o bem-estar coletivo. Suas ações e iniciativas ao longo de sua carreira refletem sua dedicação em fazer a diferença na vida das pessoas e contribuir para um mundo melhor.
Nota: As informações apresentadas são baseadas em dados disponíveis publicamente até a data de corte em janeiro de 2022. Para informações mais atualizadas, recomenda-se verificar as fontes oficiais e as redes sociais do João Ricardo Mendes e do Hurb.
Veja abaixo o relato de Pedro Corte, amigo de infância de João Ricardo Mendes.
✈️ Perguntas frequentes ✈️
João Ricardo Mendes é um empreendedor brasileiro, conhecido por ser um dos fundadores do Hurb (anteriormente conhecido como Hotel Urbano), uma das maiores agências de viagens on-line do Brasil.
O Hurb foi fundado em 2011 por João Ricardo Mendes e seu irmão, José Eduardo Mendes.
João Ricardo Mendes é reconhecido por sua visão inovadora, espírito empreendedor e compromisso com a responsabilidade social.
Ele apoia o turismo sustentável, incentiva o empreendedorismo no Brasil e participou de ações de solidariedade durante a pandemia de COVID-19.
Ele defende práticas que beneficiem os viajantes e a indústria do turismo, protegendo o meio ambiente e promovendo o bem-estar das comunidades locais.
Durante a pandemia, ele e o Hurb realizaram doações e contribuíram para iniciativas de apoio a profissionais de saúde e comunidades afetadas pela crise.
Ele oferece mentorias e apoio a jovens empreendedores e startups, compartilhando sua experiência e conhecimento no setor.
Ele investe em iniciativas educacionais, proporcionando oportunidades de aprendizado e desenvolvimento para jovens e adultos.
Para informações mais atualizadas, recomenda-se verificar as fontes oficiais e as redes sociais de João Ricardo Mendes e do Hurb.
Nos últimos anos, o Brasil tem enfrentado um aumento alarmante no número de ataque hacker. De acordo com dados recentes, o país é o maior alvo de ataques cibernéticos na América Latina, com uma tendência preocupante. No segundo semestre de 2022, o Brasil sofreu um aumento significativo de 19% no número de ataques, um percentual superior à média global de 13%. Isso representa quase 40% do total de invasões cibernéticas registradas na América Latina.
A escala dos ataques no Brasil e na América Latina
Para entender melhor a extensão desse problema, é importante considerar os números. No segundo semestre de 2022, o Brasil registrou 285.529 ataques cibernéticos. Outros países da região também foram alvo dessas ameaças, mas em uma escala menor:
Colômbia: 90.063 ataques;
Argentina: 25.800 ataques;
Equador: 24.540 ataques;
Chile: 24.184 ataques;
México: 15.328 ataques;
Peru: 14.197 ataques;
Venezuela: 2.537 ataques.
Ao todo, os 21 países que compõem a América Latina enfrentaram um número expressivo de 727.686 ataques cibernéticos durante esse período.
O que causa a vulnerabilidade do Brasil?
Várias razões contribuem para a crescente vulnerabilidade do Brasil ao ataque hacker. Primeiramente, o país possui uma vasta infraestrutura de TI e um grande número de usuários de internet, o que atrai a atenção de hackers. Além disso, muitas organizações no Brasil ainda enfrentam desafios na implementação de medidas de segurança cibernética adequadas, o que torna mais fácil para os criminosos explorar vulnerabilidades.
Como se proteger no cenário de ataques cibernéticos em ascensão
Dada a gravidade da situação, é crucial que indivíduos e organizações no Brasil estejam preparados para enfrentar um ataque hacker. Aqui estão algumas medidas essenciais:
Conscientização: esteja ciente das ameaças cibernéticas e das táticas comuns usadas pelos hackers.
Segurança de dados: garanta que os dados confidenciais sejam protegidos por meio de criptografia e políticas de acesso restritas.
Atualizações de software: mantenha todos os sistemas, aplicativos e dispositivos atualizados com as últimas correções de segurança.
Firewalls e antivírus: utilize soluções de segurança cibernética, como firewalls e antivírus, para proteger contra ameaças conhecidas.
Treinamento: eduque funcionários e usuários sobre boas práticas de segurança cibernética.
Monitoramento de rede: implemente sistemas de monitoramento de rede para detectar atividades suspeitas.
Resposta a incidentes: tenha um plano de resposta a incidentes em vigor para lidar com ataques quando ocorrerem.
Ataque DDoS
Um Ataque de Negação de Serviço Distribuído (DDoS) é uma tentativa de tornar um serviço online indisponível sobrecarregando-o com tráfego de múltiplas fontes. Eles visam uma ampla variedade de recursos importantes, desde bancos até sites de notícias, e representam um grande desafio para garantir que as pessoas possam publicar e acessar informações importantes.
Tipos de ataques
Os ataques DDoS vêm em muitas formas diferentes, desde ataques Smurf até Teardrops e Pings of Death.
Classe de Ataque: quatro categorias comuns de ataques
Ataques de Conexão TCP – ocupação de conexões
Esses ataques tentam esgotar todas as conexões disponíveis em dispositivos de infraestrutura, como balanceadores de carga, firewalls e servidores de aplicação. Mesmo dispositivos capazes de manter o estado em milhões de conexões podem ser comprometidos por esses ataques.
Ataques Volumétricos – consumindo largura de banda
Esses ataques tentam consumir a largura de banda, seja dentro da rede/serviço de destino ou entre a rede/serviço de destino e o restante da Internet. Esses ataques têm como objetivo principal causar congestionamento na rede.
Ataques de Fragmentação – fragmentos de pacotes
Esses ataques enviam uma inundação de fragmentos TCP ou UDP para uma vítima, sobrecarregando a capacidade da vítima de reagrupar os fluxos e reduzindo severamente o desempenho.
Ataques de Aplicação – mirando em aplicações
Esses ataques tentam sobrecarregar um aspecto específico de uma aplicação ou serviço e podem ser eficazes mesmo com pouquíssimas máquinas atacantes gerando uma taxa de tráfego baixa (o que os torna difíceis de detectar e mitigar).
Em resumo, o Brasil enfrenta um aumento preocupante nos ataques cibernéticos, destacando a necessidade premente de medidas de segurança cibernética robustas em todas as esferas da sociedade. Ao adotar práticas de segurança e ficar alerta para as ameaças, podemos trabalhar juntos para proteger nossos sistemas e informações valiosas contra os hackers que visam explorar nossa vulnerabilidade digital. A segurança cibernética é uma responsabilidade compartilhada por todos, e a proteção começa com a conscientização e a ação proativa.
Descobrir as causas profundas das doenças é um dos maiores desafios da genética humana. Com milhões de mutações possíveis e dados experimentais limitados, ainda é um mistério quais delas podem causar doenças. Este conhecimento é crucial para um diagnóstico mais rápido e para o desenvolvimento de tratamentos que salvam vidas.
Hoje, estamos lançando um catálogo de mutações “missenses” onde os pesquisadores podem aprender mais sobre o efeito que elas podem ter. Variantes missense são mutações genéticas que podem afetar a função das proteínas humanas. Em alguns casos, podem causar doenças como fibrose cística, anemia falciforme ou câncer.
O catálogo AlphaMissense foi desenvolvido usando AlphaMissense, nosso novo modelo de IA que classifica variantes missense. Num artigo publicado na Science , mostramos que categorizou 89% de todas as 71 milhões de possíveis variantes missense como provavelmente patogénicas ou provavelmente benignas. Por outro lado, apenas 0,1% foram confirmados por especialistas humanos.
As ferramentas de IA que podem prever com precisão o efeito das variantes têm o poder de acelerar a investigação em campos que vão da biologia molecular à genética clínica e estatística. Experimentos para descobrir mutações causadoras de doençassão caros e trabalhosos – cada proteína é única e cada experimento deve ser projetado separadamente, o que pode levar meses. Ao utilizar previsões de IA, os investigadores podem obter uma pré-visualização dos resultados de milhares de proteínas de cada vez, o que pode ajudar a priorizar recursos e acelerar estudos mais complexos.
Disponibilizamos gratuitamente todas as nossas previsões para a comunidade de pesquisa e abrimos o código do modelo do AlphaMissense .
AlphaMissense previu a patogenicidade de todas as 71 milhões de variantes missense possíveis. Classificou 89% – prevendo que 57% eram provavelmente benignos e 32% eram provavelmente patogênicos.
O que é uma variante missense?
Uma variante missense é uma substituição de uma única letra no DNA que resulta em um aminoácido diferente dentro de uma proteína. Se você pensar no DNA como uma linguagem, mudar uma letra pode mudar uma palavra e alterar completamente o significado de uma frase. Nesse caso, uma substituição altera qual aminoácido é traduzido, o que pode afetar a função de uma proteína.
Uma pessoa média carrega mais de 9.000 variantes missense . A maioria é benigna e tem pouco ou nenhum efeito, mas outras são patogênicas e podem perturbar gravemente a função das proteínas. As variantes missense podem ser usadas no diagnóstico de doenças genéticas raras, onde algumas ou mesmo uma única variante missense podem causar doenças diretamente. Eles também são importantes para o estudo de doenças complexas, como o diabetes tipo 2, que pode ser causado por uma combinação de muitos tipos diferentes de alterações genéticas.
A classificação de variantes missense é um passo importante na compreensão de quais dessas alterações proteicas podem dar origem à doença. Das mais de 4 milhões de variantes missense que já foram observadas em humanos, apenas 2% foram anotadas como patogênicas ou benignas pelos especialistas, cerca de 0,1% de todas as 71 milhões de variantes missense possíveis. As restantes são consideradas “variantes de significado desconhecido” devido à falta de dados experimentais ou clínicos sobre o seu impacto. Com o AlphaMissense, temos agora a imagem mais clara até o momento, classificando 89% das variantes usando um limite que rendeu 90% de precisão em um banco de dados de variantes de doenças conhecidas.
Patogênico ou benigno: como AlphaMissense classifica variantes
AlphaMissense é baseado em nosso modelo inovador AlphaFold , que previu estruturas para quase todas as proteínas conhecidas pela ciência a partir de suas sequências de aminoácidos. Nosso modelo adaptado pode prever a patogenicidade de variantes missense que alteram aminoácidos individuais de proteínas.
Para treinar o AlphaMissense, ajustamos o AlphaFold nos rótulos que distinguem variantes observadas em populações humanas e de primatas intimamente relacionadas. As variantes comumente observadas são tratadas como benignas e as variantes nunca observadas são tratadas como patogênicas. AlphaMissense não prevê a mudança na estrutura da proteína após mutação ou outros efeitos na estabilidade da proteína. Em vez disso, utiliza bases de dados de sequências de proteínas relacionadas e contexto estrutural de variantes para produzir uma pontuação entre 0 e 1, classificando aproximadamente a probabilidade de uma variante ser patogénica. A pontuação contínua permite que os usuários escolham um limite para classificar variantes como patogênicas ou benignas que atenda aos seus requisitos de precisão.
Uma ilustração de como AlphaMissense classifica variantes missense humanas. Uma variante missense é inserida e o sistema de IA a classifica como patogênica ou provavelmente benigna. AlphaMissense combina contexto estrutural e modelagem de linguagem de proteínas e é ajustado em bancos de dados de frequência de populações de variantes humanas e primatas.
AlphaMissense alcança previsões de última geração em uma ampla gama de benchmarks genéticos e experimentais, tudo sem treinamento explícito em tais dados. Nossa ferramenta superou outros métodos computacionais quando usada para classificar variantes do ClinVar, um arquivo público de dados sobre a relação entre variantes humanas e doenças. Nosso modelo também foi o método mais preciso para prever resultados de laboratório, o que mostra que é consistente com diferentes formas de medir a patogenicidade.
AlphaMissense supera outros métodos computacionais na previsão de efeitos de variantes missense.
Esquerda:
Comparando o desempenho do AlphaMissense e de outros métodos na classificação de variantes do arquivo público Clinvar.
Os métodos mostrados em cinza foram treinados diretamente no ClinVar e seu desempenho neste benchmark é provavelmente superestimado, uma vez que algumas de suas variantes de treinamento estão contidas neste conjunto de testes. À direita: gráfico comparando o desempenho do AlphaMissense e de outros métodos na previsão de medições de experimentos biológicos.
Construindo um recurso comunitário
AlphaMissense baseia-se no AlphaFold para promover a compreensão mundial das proteínas. Há um ano, lançámos 200 milhões de estruturas proteicas previstas através do AlphaFold – que está a ajudar milhões de cientistas em todo o mundo a acelerar a investigação e a preparar o caminho para novas descobertas. Estamos ansiosos para ver como o AlphaMissense pode ajudar a resolver questões em aberto no cerne da genômica e em toda a ciência biológica.
Disponibilizamos gratuitamente as previsões do AlphaMissense para a comunidade científica. Juntamente com o EMBL-EBI, também os estamos tornando mais utilizáveis para pesquisadores por meio do Ensembl Variant Effect Predictor .
Além de nossa tabela de pesquisa de mutações missense, compartilhamos as previsões expandidas de todas as possíveis 216 milhões de substituições de sequências de aminoácidos únicas em mais de 19.000 proteínas humanas. Também incluímos a previsão média para cada gene, que é semelhante a medir a restrição evolutiva de um gene – isto indica o quão essencial o gene é para a sobrevivência do organismo.
Exemplos de previsões AlphaMissense sobrepostas em estruturas previstas AlphaFold (vermelho = previsto como patogênico, azul = previsto como benigno, cinza = incerto). Os pontos vermelhos representam variantes missense patogênicas conhecidas, os pontos azuis representam variantes benignas conhecidas do banco de dados ClinVar.
Esquerda: proteína HBB. Variantes desta proteína podem causar anemia falciforme. À direita: proteína CFTR. Variantes desta proteína podem causar fibrose cística.
Acelerando a pesquisa sobre doenças genéticas
Um passo fundamental na tradução desta pesquisa é colaborar com a comunidade científica. Temos trabalhado em parceria com a Genomics England para explorar como estas previsões podem ajudar a estudar a genética das doenças raras. A Genomics England cruzou as descobertas da AlphaMissense com dados de patogenicidade variante previamente agregados com participantes humanos. A avaliação deles confirmou que nossas previsões são precisas e consistentes, fornecendo outra referência do mundo real para a AlphaMissense.
Embora as nossas previsões não sejam concebidas para serem utilizadas diretamente na clínica – e devam ser interpretadas com outras fontes de evidência – este trabalho tem o potencial de melhorar o diagnóstico de doenças genéticas raras e ajudar a descobrir novos genes causadores de doenças.
Em última análise, esperamos que o AlphaMissense, juntamente com outras ferramentas, permita aos investigadores compreender melhor as doenças e desenvolver novos tratamentos que salvem vidas.
Hurb fortalece sua jornada na nuvem com Machine Learning, Big Data e novas estratégias. A transformação propiciada pelo Google Cloud, que começou com ganho de escalabilidade e economia, culminou na melhor gestão e armazenamento de dados, garantindo a internacionalização dos processos.
Resultados do Google Cloud
Otimização de uma base de mais de 1,5 milhão de hotéis em todo o mundo
Redução de custos em 21%, com estimativa de chegar a 40% em alguns anos
Permissão de acesso a dados para mais de 700 colaboradores
Picos de utilização do aplicativo por 9 mil pessoas simultaneamente
Integração e colaboração das equipes com o Google Workspace
Redução do tempo de consulta de horas para segundos
O Hotel Urbano (Hurb) é uma das principais plataformas de viagens online do Brasil. A companhia tem como missão criar soluções para otimizar e tornar as viagens mais fáceis e acessíveis para todos, conectando pessoas e lugares. Com sede no Rio de Janeiro e atuação em todo o Brasil e no exterior, a empresa já conta com escritórios em Sorocaba (SP), Portugal e, em breve, no Canadá.
Acompanhando a premissa de inovação, a empresa, que nasceu ainda em servidores físicos, migrou para a nuvem em pouco tempo de existência. Entretanto, ainda assim havia a preocupação de resolver alguns desafios técnicos de escalabilidade para manter o crescimento do negócio de forma exponencial.
Desde que escolheu migrar sua infraestrutura para o Google Cloud, em 2016, a companhia deixou de se preocupar com diversas questões de infraestrutura. O time do Google foi essencial para auxiliar nesse caminho.
“Durante toda a migração para o Google Cloud, sempre recebemos apoio de Googlers para troca de várias informações sobre tecnologia. Quando precisamos de uma particularidade de um produto específico, conseguimos alinhar com os engenheiros do Google e, às vezes, se necessário, usamos a versão Beta cerca de quatro meses antes de estar disponível em produção. Em todo o processo não tivemos nenhum parceiro envolvido, somente a equipe do Google e a nossa equipe trabalhando em conjunto,” conta Leandro Souza, Head de Infraestrutura do Hurb.
Benefícios contabilizados em curto prazo
Desde a sua fundação, a empresa primava pelo estabelecimento de uma multizona para seus usuários e, ao mesmo tempo, pela robustez e elasticidade. Com a utilização do Google Kubernetes Engine, tornou-se possível assegurar o balanceamento de carga e distribuir os usuários nos microsserviços. Caso necessário, o recurso Horizontal Pod Autoscaler (HPA) dá conta da demanda, alocando mais contêineres para atender os usuários.
A nova infraestrutura também permitiu uma redução de servidores, com pico em número de usuários utilizando simultaneamente o aplicativo do Hurb. Outras conquistas com a nuvem foram a otimização do atendimento ao usuário e a maturidade para testar as ferramentas previamente para, então, disponibilizar aos utilizadores.
“Houve uma redução tão grande de erros, que alguns usuários até pensaram que o sistema não estava funcionando direito, pelas experiências anteriores à migração,” afirma o Head de Infraestrutura.
Como o Hurb já operava na nuvem, a necessidade de adaptação de infraestrutura foi facilitada. A equipe migrou algumas aplicações antigas em máquinas virtuais para contêineres e encaixou os mais de 86 microsserviços no novo sistema. Dois anos e meio após a migração, a empresa registrou uma redução de custos de 21%, e estima chegar a 40% nos anos seguintes.
“Ganhamos muito em escalabilidade e não precisamos adaptar a infraestrutura, só encaixar nossos mais de 86 microsserviços que tínhamos em 2019 no novo sistema de orquestração do Google Cloud. Também tivemos uma redução de 82 servidores para apenas 39, e chegamos a ter 9 mil pessoas simultaneamente no aplicativo.”
Projeto de expansão Global
Ao avaliar todos os bons resultados, a empresa entendia que ainda existiam alguns desafios técnicos que garantiriam o crescimento da plataforma de modo exponencial. Foi quando surgiu a ideia da aposta em Machine Learning e Big Data, em mais uma parceria com o Google Cloud, para a retomada das atividades do setor de turismo no período pós-pandemia. O objetivo era trazer inteligência ao trabalho dos colaboradores.
Como resultado, após a utilização das soluções em nuvem, o Hurb conseguiu resolver problemas de duplicidade de ofertas, democratizou o acesso às informações para os funcionários e passou a processar e armazenar dados de forma mais rápida e inteligente.
Atualmente, o Hurb vende uma diária a cada cinco segundos. Juntamente com a combinação entre o Google Geocoding API e sistemas proprietários de Machine Learning, a empresa passou a identificar estabelecimentos duplicados e semelhantes de seus diversos parceiros e a otimizar uma base de mais de 1,5 milhão de hotéis em todo o mundo.
Integrando a API Vision aos seus sistemas proprietários de dados, a companhia pôde compreender as milhões de imagens que representam seus produtos, assim como selecionar automaticamente a melhor imagem para seus clientes.
“A parceria com a nuvem proporcionou uma mudança cultural no Hurb. As nossas equipes passaram a ter acesso aos dados, acarretando uma performance baseada em métricas e, consequentemente, maior compromisso dos colaboradores com os resultados.”
Outro benefício da parceria foi a internacionalização da operação do Hurb, que foi possível graças à adoção da API Translation, solução do Google Cloud que traduz textos instantaneamente para mais de 100 idiomas.
Por sua vez, com as soluções Dataflow, Dataform e BigQuery, o processamento e o armazenamento de grandes volumes de dados tornaram-se uma realidade, instituindo uma forma muito mais rápida e inteligente, que fornece insights de negócios em tempo real para a empresa, sendo uma das primeiras empresas do mundo a adotar tal tecnologia.
Como saldo positivo, a companhia concedeu acesso a dados para mais de 900 colaboradores, reduziu o tempo de consulta aos dados de horas para segundos, passou a gerir mais de 2,5 mil tabelas com informações sobre o setor de turismo e reduziu a quantidade de erros em tabelas e o tempo para disponibilização dos dados.
Google Workspace para colaboração com o valor “Itá All about people”
Além de todas as implementações e mudanças propiciadas pela nuvem, o Google Workspace veio para complementar essa verdadeira jornada de bons resultados por parte do Hurb.
Nesse sentido, ao adotar as ferramentas do Google Workspace, os profissionais da empresa conseguem mensurar e compreender como as atividades são feitas, bem como gerir melhor o tempo.
O Planilhas é um dos exemplos que facilita a gestão dos dados e tarefas. Por meio de uma trilha de desenvolvimento de liderança, planejamento e novas ações, o Drive é utilizado para compartilhar documentos, assegurando o acesso das pessoas a todos os dados simultaneamente.
“Toda a nossa documentação é viva no Drive. Nós criamos um documento e o aprimoramos. Isso serve para parcerias e para nos nortear em diversos momentos dentro da companhia. Além disso, no Gmail, a comunicação é fluida com contas sincronizadas, o que nos poupa tempo.”
João Ricardo Mendes, CEO Global do Hurb
Sobre Hurb
Consolidando-se como destaque quando o assunto é plataforma e tecnologia para viagens online, Hurb busca alternativas para otimizar, simplificar e trazer fácil acesso às viagens, conectando pessoas e lugares e fazendo com que milhões de Brasileiros tenham sua primeira experiência de viagem.
Vivemos em um mundo com uma explosão de informações. Há milhões de roupas, músicas, filmes, receitas, carros, casas, qual você deve escolher? A pesquisa semântica pode encontrar a certa para qualquer gosto e desejo!Neste artigo, vou apresentar o que é pesquisa semântica, o que pode ser construído com ela e como construí-la. Por exemplo, por que as pessoas procuram roupas?
Eles gostam da marca, da cor, da forma ou do preço. Todos esses aspectos podem ser usados para encontrar o melhor.A cor e a forma podem ser encontradas usando a imagem, e o preço e a marca são encontrados nas tendências.Imagens e tendências podem ser representadas como pequenos vetores chamados incorporações.
As incorporações são o núcleo da pesquisasemântica: uma vez que os itens são codificados como vetores, é rápido e eficiente procurar os melhores itens.Vou explicar como a pesquisa semântica funciona: codificar itens como incorporações, indexá-los e usar esses índices para pesquisa rápida, a fim de construir sistemas semânticos.
1. Motivação: por que pesquisar, por que pesquisar semântica?
1.1 O que é pesquisa?
Por milhares de anos, as pessoas quiseram pesquisar entre documentos: pense nas enormes bibliotecas que contêm milhões de livros. Foi possível então procurar nesses livros graças às pessoas que os classificassem cuidadosamente por nomes de autores, data de publicação,… Os índices dos livros foram cuidadosamente construídos e foi possível encontrar livros pedindo a especialistas.Há 30 anos, a internet se tornou popular e, com ela, o número de documentos para pesquisar passou de milhões para bilhões. A velocidade com que esses documentos passaram de alguns milhares todos os anos para milhares todos os dias, não era mais possível indexar tudo manualmente.Foi quando sistemas de recuperação eficientes foram construídos. Usando a estrutura de dados apropriada, é possível indexar bilhões de documentos todos os dias automaticamente e consultá-los em milissegundos.A pesquisa é sobre atender a uma necessidade de informação. Começando por usar uma consulta de qualquer forma (perguntas, lista de itens, imagens, documentos de texto,…), o sistema de pesquisa fornece uma lista de itens relevantes. Os sistemas de pesquisa clássicos constroem representações simples a partir de texto, imagem e contexto e constroem índices eficientes para pesquisar a partir deles. Alguns descritores e técnicas incluem
As semelhanças de itens são um método clássico para encontrar itens semelhantes usando classificação e tendências
Embora esses sistemas possam ser dimensionados para quantidades muito grandes de conteúdo, eles geralmente sofrem de dificuldades para lidar com o significado do conteúdo e tendem a permanecer no nível da superfície.Essas técnicas clássicas de recuperação fornecem bases sólidas para muitos serviços e aplicações. No entanto, eles não conseguem entender completamente o conteúdo que estão indexando e, como tal, não podem responder de maneira relevante a algumas perguntas sobre alguns documentos. Veremos nas próximas seções como as incorporações podem ajudar.
1.2 O que é pesquisa semântica e o que pode ser construído com ela?
A principal diferença entre a pesquisa clássica e a pesquisa semântica é usar pequenos vetores para representar itens.
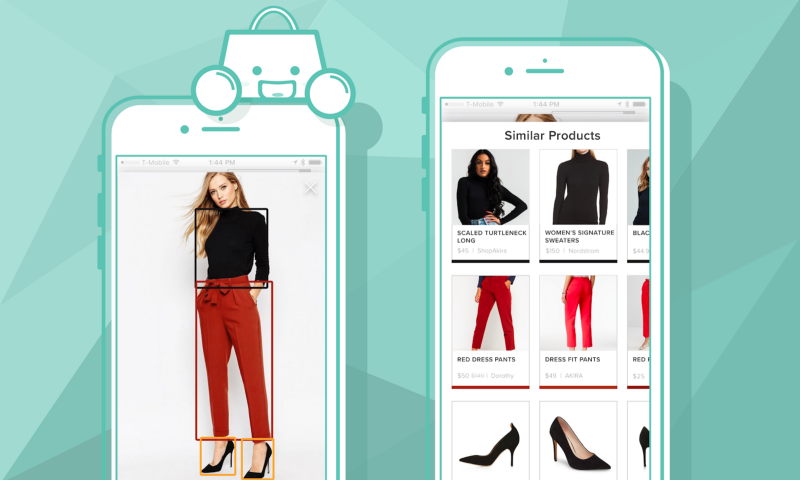
A pesquisa visual pode ser usada para procurar plantas PlantNet, mas também para procurar roupas
O uso de incorporações é poderoso: pode ser usado para criar sistemas que podem ajudar os usuários a encontrar itens de que gostam (música, produto, vídeos, receitas, …) usando muitos tipos de consultas. Ele não pode funcionar apenas em sistemas de pesquisa explícitos (inserindo uma consulta em uma barra de pesquisa), mas também em sistemas implícitos (produtos relevantes em sites de varejistas, notícias personalizadas em editores, postagens interessantes em plataformas sociais).Muitos tipos de sistemas podem ser construídos em cima da pesquisa.
Um sistema de pesquisa de texto leva como entrada uma consulta de texto e retorna resultados: pesquisa de roupas, músicas, notícias
Um sistema de pesquisa visual toma como entrada uma imagem e retorna itens semelhantes em comparação com esta imagem.
Um sistema de recomendação usa como entrada algum contexto, informações do usuário e retorna itens semelhantes que otimizam para um determinado objetivo: recomendar filmes, carros, casas
Redes sociais, redes de publicidade, mecanismos de busca especializados (pesquisa de produtos) usam técnicas de recuperação para fornecer as melhores informações
É possível pesquisar uma variedade de itens, qualquer coisa que tenha imagens, texto, áudio ou esteja disponível em um contexto. Exemplos populares de tais sistemas são a lente do Google, a recomendação da Amazon ou os mais novos para pesquisa de moda, pesquisa de plantas, …Em menor escala, pode ser interessante indexar suas fotos, suas mensagens, encontrar um programa de TV entre muitos, encontrar atores em um programa de TV, …
2. Design geral: como construir pesquisa semântica?
Um sistema de pesquisa semântica é composto por duas partes: um pipeline de codificação que constrói índices e um pipeline de pesquisa que permite ao usuário usar esses índices para pesquisar itens.
3 Pipeline de codificação: de itens a vetores e índices
O primeiro passo para construir um sistema de recuperação semântica é codificar itens em pequenos vetores (centenas de dimensões). Isso é possível para muitos itens e pode ser usado para indexá-los e pesquisar entre eles de forma eficiente.
3.1 Extraia dados relevantes
Os sistemas de recuperação podem codificar itens de muitos aspectos diferentes, por isso é importante pensar no que codificar. Alguns exemplos de itens para codificar são roupas, brinquedos, animais, notícias, músicas, filmes, receitas. Cada um deles tem características diferentes: eles podem ser expressos por como se parecem, como podem ser descritos, como aparecem entre outros itens.Todas essas informações podem ser codificadas como incorporações. Um eixo diferente para pensar é quantos itens codificar? Todos os itens são únicos ou faz mais sentido agrupá-los por características relevantes? Existem alguns itens que são mais relevantes e devem ser uma prioridade? Fazer essa escolha cedo pode ter consequências dramáticas para o resto do sistema.
Este personagem de Star Wars C-3PO pode ser codificado com uma imagem dele, uma descrição, como ele aparece em um gráfico (está em um filme de Star Wars, aparecendo na data desses filmes, …), quão popular ele é, mas também que ele aparece junto com R2-D2 com frequência, e tem uma voz robótica. Todas essas informações podem ser relevantes. Qual escolher pode afetar muito o desempenho do sistema.
Para um sistema de recomendação, as informações de co-ocorrência podem funcionar melhor, mas para um sistema de pesquisa visual, a imagem pode ser a mais relevante.
3.2 Codifique os itens
3.2.1 Conteúdo
Os itens podem ser codificados com base em seu conteúdo. As roupas podem ser bem representadas com imagens. Os sons são identificados por seu conteúdo de áudio. As notícias podem ser entendidas usando seu texto. Os modelos de aprendizagem profunda são muito bons em produzir representações de conteúdo que têm boas propriedades de recuperação.
As imagens podem ser representadas com incorporações (leia uma introdução sobre isso no meu post anterior). Redes como ResNet ou EfficientNet são realmente bons extratores de recursos para imagens, e muitas redes pré-treinadas estão disponíveis.Também não é apenas possível representar toda a imagem, mas também é possível usar segmentação ou detecção de objetos antes de aplicar o codificador de imagem.
A segmentação pode ser usada para extrair parte da imagem pixel por pixel, pode ser relevante para extrair camisas e calças de uma imagem de moda
A detecção é útil para extrair zonas retangulares das imagens
Uma diferença importante nos vários codificadores de imagem é qual perda eles estão usando. As redes convolucionais são frequentemente treinadas usando perda tripla, entropia cruzada ou, mais recentemente, perda contrastiva. Cada perda pode fornecer características diferentes para incorporações: perda tripla e perda contrastiva tentam montar itens semelhantes, enquanto a entropia cruzada reunirá itens da mesma classe. Muitos modelos pré-treinados são treinados na ImageNet com entropia cruzada para classificação de imagens, mas o aprendizado auto-supervisionado (simclr byol) está mudando rapidamente isso para tornar possível o treinamento não supervisionado sem classificação. Em um futuro próximo, os melhores codificadores podem não precisar de dados rotulados. Este tutorial em vídeo do CVPR2020 é muito bom para entrar em detalhes sobre recuperação de imagens.Ser capaz de codificar imagens como vetores torna possível construir muitos aplicativos: qualquer coisa que possa ser vista e assistida é algo que possa ser codificada. Pesquisa visual de moda, pesquisa de plantas, pesquisa de produtos são possíveis. A pesquisa em filmes e outros conteúdos de vídeo também se torna possível.
3.2.1.2 Texto
O texto também pode ser representado com incorporações. O texto pode ter várias formas e comprimentos: palavras, frases, documentos. A aprendizagem profunda moderna agora pode representar a maioria daqueles em representação poderosa.
Word2vec: a codificação de palavras é uma das formas mais populares de incorporação. A partir do contexto das palavras nos documentos, é possível inferir quais palavras estão mais próximas em significado às outras. Word2vec ilustrado e word2vec explicados introduzem bem o conceito e os métodos
Os transformadores são um método mais novo que torna possível codificar frases inteiras, levando melhor em conta as dependências entre muitas palavras nas frases. Alguns anos atrás, eles foram capazes de se tornar o estado da arte em muitas tarefas. O transformador ilustrado é uma introdução interessante a eles.
Arquitetura Bert: finalmente, a arquitetura Bert é um tipo especial de transformador que pode ser bem treinado em um ambiente multitarefa. Foi chamado de momento ImageNet de PNL. bert ilustrado é uma boa introdução a ele.
Na prática, alguns bons codificadores para texto podem ser:
Incorporações de palavras de luvas. Este pequeno exemplo de repositório word-knn que eu construí pode ajudar a começar rapidamente
O modelo labse para incorporações de frases é um modelo bert pré-treinado que pode codificar incorporações de até 109 idiomas em um único espaço
As incorporações de documentos podem ser representadas como a média das frases.
Ser capaz de codificar texto como vetores torna possível pesquisar artigos, descrição de filmes, títulos de livros, parágrafos da Wikipédia, … Muito conteúdo está disponível como texto, portanto, usar essas informações para um sistema de recuperação pode ser um dos primeiros passos a tentar.
3.2.1.3 E todos os outros conteúdos
Além do texto e da imagem, o conteúdo de áudio também pode ser codificado como incorporações (pense em aplicativos como o Shazam).Exemplos de Jina e vectorhub fornecem muitos bons exemplos de como codificar incorporações usando conteúdo
3.2.1.4 Escalando
Para codificar não apenas algumas centenas, mas bilhões de incorporações, trabalhos de lote como spark ou Pyspark podem ser realmente úteis. A maioria dos modelos de imagem e texto será capaz de codificar milhares de amostras por segundo. Codificar um bilhão de amostras em uma hora exigiria cerca de 300 executores.
A codificação de itens por seu conteúdo funciona bem e escala para bilhões de itens. Mas o conteúdo não é o único dado disponível, vamos ver como os outros itens podem ser codificados.
3.2.2 Distribuição: tendências
Itens como roupas, filmes e notícias geralmente estão presentes em sites visitados por muitos usuários. Os usuários interagem com os itens, gostam ou não, alguns itens são populares, alguns itens são vistos apenas por partes dos usuários e itens relacionados geralmente são vistos juntos. Tudo isso são dados de interação. Esses dados de interação podem ser usados para codificar itens. Isso é particularmente útil para definir incorporações para as quais a métrica de distância é baseada em como as pessoas interagem com esses itens sem precisar de nenhuma informação sobre seu conteúdo.
3.2.2.1 SVD
Um primeiro método para construir essa incorporação de comportamento é SVD: decomposição de valor singular.
No contexto em que para um conjunto de itens (notícias, produtos, restaurantes,…) classificações de usuários estão disponíveis, é possível calcular incorporações de usuários e itens. O primeiro passo é calcular uma matriz de similaridade de item de usuário e usando fatoração de matriz (SVD), incorporações de usuário e incorporações de itens são computadas. O svd de item de usuário é uma introdução simples a esse processo.
Outra configuração aparece quando é possível observar co-ocorrências entre itens. Um exemplo poderia ser produtos (roupas, casas, laptops, …) que são visualizados ou comprados juntos por um usuário. Essas co-ocorrências podem ser expressas com seu PMI e essa matriz item-item pode ser fatorada com SVD em incorporações de itens. Essas duas postagens de blog fornecem uma boa introdução.
Essa maneira de codificar itens em incorporações é particularmente poderosa para codificar as preferências e o comportamento do usuário em relação aos itens sem precisar de nenhum conhecimento sobre esses itens. Isso significa que ele pode funcionar em todos os idiomas e para itens onde nenhum conteúdo está disponível.
3.2.2.2 Incorporação de gráficos
Uma segunda maneira de codificar itens usando sua distribuição é a incorporação de gráficos.
Muitos conjuntos de dados podem ser representados como gráficos. Um bom exemplo é um gráfico de conhecimento. Wikidata e DBpedia, por exemplo, representam o conhecimento no mundo real como entidades como pessoas, empresas, países, filmes… e relações entre eles, como cônjuge, presidente, nacionalidade, ator.
Wikidata representa o conhecimento sobre as entidades mundiais
Isso forma um gráfico: entidades são nós no gráfico, e esses nós são ligados por arestas que são relações.
Existem muitos algoritmos interessantes e artigos recentes sobre incorporações de gráficos e redes neurais de gráficos em geral (este canal de telegrama é ótimo para seguir o tópico), mas um simples e escalável é o Pytorch Big Graph. Este ajudante que construí com um colega pode ajudar a construir grandes conjuntos de dados gráficos para PBG e visualizar alguns resultados knn.
Essa representação de dados como um gráfico pode ser usada para construir incorporações para nós e transformação para arestas que possibilitam ir de um nó para o outro. A ideia é aprender a mapear um nó para outro nó usando ambas as incorporações de nós e uma transformação que pode ser aprendida para a borda. Tal transformação pode ser uma tradução. Isso dá resultados surpreendentemente bons para prever a próxima vantagem.
O PBG possibilita aprender a transformação entre bilhões de incorporações
A contribuição do Pytorch Big Graph é particionar os nós e arestas para que seja possível aplicar esse aprendizado a centenas de milhões de nós e bilhões de arestas.
Os gráficos são muito versáteis e podem não apenas representar gráficos de conhecimento, mas também links entre usuários, produtos, restaurantes, filmes, … Usar incorporações de gráficos pode ser uma boa maneira de usar a distribuição de itens para codificá-los.
3.2.3 Composição e multimodal
Agora temos incorporações de itens de várias perspectivas, e eles podem oferecer informações complementares. Como uma peça de roupa se parece, como os usuários interagem com ela e como ela é descrita podem ser relevantes.
Como essas incorporações podem ser combinadas em uma única?
Concatenação: concatenar as incorporações é um método básico que funciona surpreendentemente bem. Por exemplo, a concatenação de incorporações de texto e imagem torna possível pesquisar um item usando seu texto, sua imagem ou ambos.
Modelo multimodal: a aprendizagem profunda da visão e da linguagem está se tornando muito popular, e muitos modelos (imagebert, vilbert, uniter, vl-bert, veja esta demonstração interessante) propõem aprender com a linguagem e o texto, para produzir representações de modelos cruzados.
Ajustando uma rede para uma tarefa específica usando várias incorporações
A composição é uma ferramenta poderosa e pode ser usada para ter uma visão completa dos itens a serem codificados.
3.2.4 Popularidade
Um tópico importante a ser considerado nos sistemas de recuperação e recomendação é a popularidade dos itens. Mostrar itens impopulares geralmente resulta em resultados não relevantes.
Uma maneira simples de resolver esse problema é adicionar um termo de popularidade à incorporação. Por exemplo, o último componente pode ser o inverso do registro do número de visualizações desse item. Dessa forma, a distância L2 entre uma consulta com um 0 no componente de popularidade classificará em primeiro lugar os itens mais populares. Isso pode ajudar a remover alguns dos itens impopulares dos principais resultados, mas isso não é perfeito, pois o trade-off entre semelhança e popularidade deve ser definido manualmente.
Treinar as incorporações para um objetivo específico é uma maneira melhor de resolver isso.
3.2.5 Treinamento
Para codificar itens, modelos de conteúdo pré-treinados e métodos baseados em distribuição funcionam bem, mas para ajustar as incorporações para uma determinada tarefa, a melhor maneira é treinar um novo modelo para isso.
Muitas tarefas podem ser consideradas para treinar incorporações: baseadas em conteúdo, baseadas em distribuição e para objetivos mais específicos, como engajamento, cliques ou talvez até mesmo felicidade do usuário.
3.2.5.1 Treinamento específico de imagem
As incorporações de imagens podem ser treinadas com tarefas como classificação, identificação, segmentação. Groknet é um bom exemplo de um grande sistema para aprender incorporações de imagens com objetivos específicos… Ele aprende em muitos conjuntos de dados díspares para muitas tarefas diferentes.
Groknet: usando um tronco de visão para treinar incorporações com muitos tipos de conjuntos de dados e perdas.
FaceNet é outra maneira simples de treinar incorporações de imagens além da classificação. A perda tripla permite que ele aprenda um tipo específico de incorporação de imagem: incorporação de rosto. Isso pode ser reutilizado para outros exemplos, como incorporação de ursos de treinamento
3.2.5.2 Treinamento específico do texto
Bert é um ótimo exemplo de um modelo que pode ser ajustado e reutilizado para vários objetivos. Em particular, a biblioteca de transformadores huggingface e a biblioteca de transformadores thesentence com base nela são ótimas para ajustar um modelo de texto para um caso de uso específico. Centenas de arquiteturas de transformadores diferentes estão disponíveis lá com dezenas de configurações de treinamento.
3.2.5.3 Distribuição: treinamento específico de recomendação
Incorporações de ajuste fino para recomendação
Outra configuração é um modelo de treinamento para recomendação. Isso pode funcionar muito bem para ir além do SVD e treinar incorporações de produtos e usuários. A biblioteca criteodeepr com seu blog que o acompanha é uma boa introdução a este tópico. Os recomendadores do Tensorflow são outro bom ponto de entrada.
3.2.5.1 E muito mais
Além dessas configurações de treinamento específicas, as incorporações de treinamento são o núcleo da aprendizagem profunda e da aprendizagem de representação. Pode ser aplicado em muitos ambientes e para muitos objetivos. Alguns exemplos interessantes são:
StarSpace, um projeto do Facebook para aprender incorporações de imagens, texto, gráfico e distribuição para vários objetivos
Incorporação de receitas um exemplo de um projeto para aprender incorporações de receitas a partir de ingredientes, instruções e imagens
Para se aprofundar mais neste tópico de treinamento de redes neurais para recuperação de informações, esses slides do ecir2018 estão bastante completos.
3.3 Construa índices relevantes
Uma vez que as incorporações são construídas, precisamos de uma maneira de olhar entre elas rapidamente. Isso pode ser alcançado graças ao algoritmo k do vizinho mais próximo. A versão simples consiste em calcular uma distância entre um vetor e todos os vetores do conjunto de dados. Isso pode ser melhorado muito usando algoritmos aproximados de k vizinhos mais próximos.
Usando a implementação correta dos índices knn, é possível procurar os vizinhos mais próximos de uma incorporação a partir de um conjunto de bilhões de vetores em milissegundos. Graças às técnicas de quantização, isso pode caber em apenas alguns GB de memória.
3.3.1 O que indexar, quantos índices?
Em termos de desempenho, as coisas importantes a serem otimizadas ao construir índices são:
Latência: quanto tempo leva para um índice retornar resultados?
Lembre-se: quantos dos resultados de um knn de força bruta são encontrados no resultado do índice?
Memória: quão grande é o índice, quanta memória é necessária para mantê-lo na ram?
Em termos de relevância de pesquisa, pode ser importante particionar as incorporações nas dimensões certas. Por exemplo, os itens podem ser particionados por categorias amplas (calças, camisetas,…) para um aplicativo de pesquisa visual de moda. Esse particionamento pode ter consequências ao construir os índices, por isso é melhor decidir cedo.
3.3.2 Aproximado knn e bibliotecas
Para escolher a melhor maneira de construir índices, o número de incorporações é um bom discriminador.
Alguns exemplos de algoritmos apropriados podem ser:
Para menos de mil incorporações, uma busca de força bruta faz sentido
Por menos de um milhão, um algoritmo rápido, mas não eficiente em termos de memória (como HNSW) é apropriado
Por menos de um bilhão, a quantização (usando k-means e fertilização in vitro) se torna importante
Para um exemplo trilhão, a única solução são os índices em disco
Alguns algoritmos para calcular knn aproximado são:
Um knn ingênuo: que pode ser implementado em O(nlog(k)) com uma fila de prioridade ou O(n) com quickselect ou introselect. Para poder calcular isso, é necessário armazenar todas as incorporações na memória.
HNSW: um algoritmo que constrói um gráfico de vizinhos. É O(log(N)) na pesquisa, mas não é exato. Leva cerca de duas vezes a memória das incorporações porque precisa armazenar o gráfico
FIV: o algoritmo de arquivo invertido consiste em dividir o espaço de incorporação em várias partes e usar k-means para encontrar uma aproximação de incorporação. É menos rápido que o HNSW, mas permite diminuir a memória exigida pelo índice tanto quanto necessário.
Para saber mais sobre todos os tipos de índices, recomendo ler esta página da documentação do faiss. Este tutorial do CVPR2020 se aprofunda sobre esses algoritmos, aconselho assisti-lo se você estiver interessado em entender os detalhes mais finos.
As bibliotecas que implementam esses índices incluem:
Faiss Uma biblioteca muito ampla que implementa muitos algoritmos e interfaces limpas para construí-los e pesquisar a partir deles
Hnswlib é atualmente a implementação mais rápida de HNSW. Altamente especializado e otimizado
Annoy é outro algoritmo knn, implementado pelo Spotify
Como o knn aproximado está no centro da recuperação moderna, é um campo de pesquisa ativo. Notavelmente, esses artigos recentes introduzem novos métodos que superam algumas métricas.
Scann do Google é um novo método que é de última geração, superando HNSW em velocidade e recall usando quantização anisotrópica
Catalisador do Facebook que propõe treinar o quantizador com uma rede neural para uma tarefa específica
Eu aconselho começar pelo faiss por sua flexibilidade e tentar outras bibliotecas para necessidades específicas.
3.3.3 Escala
Para ser capaz de escalar para muitas incorporações, as técnicas principais são:
Quantificação: as incorporações podem ser compactadas em índices de tamanho 1/100 e mais
Sharding: particionar os itens ao longo de uma dimensão, torna possível armazenar os índices em diferentes máquinas
Para escalar em termos de velocidade, a velocidade do índice é realmente importante (algoritmos como HNSW podem ajudar muito), mas servir também é crucial. Mais detalhes sobre isso na seção de serviço.
Em termos práticos, é possível construir um índice de 200 milhões de incorporações com apenas 15 GB de memória RAM e latências em milissegundos. Isso desbloqueia sistemas de recuperação baratos na escala de um único servidor. Isso também significa que, na escala de alguns milhões de incorporações, os índices knn podem caber em apenas centenas de megabytes de memória, que podem caber em máquinas de mesa e até mesmo dispositivos móveis.
3.3.4 Índices Knn como um componente de banco de dados
Bancos de dados existem em todos os tipos: bancos de dados relacionais, armazenamentos de chaves/valores, bancos de dados de gráficos, armazenamentos de documentos,… Cada tipo tem muitas implementações. Esses bancos de dados trazem maneiras convenientes e eficientes de armazenar informações e analisamos-las. A maioria desses bancos de dados fornece maneiras de adicionar novas informações e consultá-las pela rede e usar APIs em muitos idiomas. Esses bancos de dados em seu núcleo estão usando índices para torná-los rápidos para consultá-los. Os bancos de dados relacionais em seu núcleo usam mecanismos de armazenamento (como o InnoDB) que usam índices adaptados. As lojas de chaves/valor implementam índices baseados em hash compartilhados e distribuídos.
E se os índices knn pudessem ser integrados às implementações de banco de dados como apenas mais um tipo de índice?
Isso é o que é proposto por projetos como
Uma integração de pesquisa elástica de HNSW: eles propõem adicionar hnsw como parte do banco de dados geral de pesquisa elástica. Isso torna possível combinar a pesquisa knn com consultas rigorosas, consultas de texto e junções fornecidas pela pesquisa elástica
Unicorn, um sistema privado do Facebook que permite integrar a pesquisa knn em um banco de dados de gráficos. Como consequência, as consultas nesse gráfico podem ter partes usando consultas knn.
Além desses sistemas específicos, o que eu acho realmente interessante nesse conceito é a ênfase em tornar a construção de índices knn um processo simples que pode ser acionado facilmente:
A adição de novos dados aciona automaticamente a reindexação ou a adição direta de incorporações aos índices existentes
Escolhendo automaticamente o tipo certo de índice knn com base na restrição específica do sistema
4. Pipeline de pesquisa: de índices a sistemas de pesquisa semântica
O pipeline de pesquisa é a parte do sistema que geralmente é executada em uma configuração on-line e de baixa latência. Seu objetivo é recuperar resultados relevantes para uma determinada consulta. É importante que ele retorne resultados em segundos ou milissegundos, dependendo das restrições e para ocupar baixas quantidades de memória.
É composto por uma maneira de extrair dados relevantes de uma consulta, um codificador para transformar esses dados em incorporações, um sistema de pesquisa que usa índices construídos no pipeline de codificação e, finalmente, um sistema de pós-filtragem que selecionará os melhores resultados.
Ele pode ser executado em servidores, mas para uma quantidade menor de itens (milhões), também pode ser executado diretamente no lado do cliente (navegadores e dispositivos pequenos).
4.1 Extraia partes de consultas
A primeira parte do sistema consiste em pegar uma consulta como entrada e extrair dados relevantes dela para poder codificá-la como incorporações de consulta.
Alguns exemplos interessantes de consultas incluem procurar roupas semelhantes, procurar uma planta de uma foto, procurar músicas semelhantes de um registro de áudio. Outro exemplo pode ser uma lista de itens vistos pelos usuários.
A consulta pode assumir qualquer forma: uma imagem, texto, uma sequência de itens, áudio, …
Para poder codifico-lo da melhor maneira, várias técnicas podem ser usadas:
Para uma segmentação de imagem ou detecção de objetos pode ser relevante: extrair apenas roupas da foto de uma pessoa, por exemplo
Para texto, pode ser relevante extrair entidades nomeadas da consulta, pode fazer sentido aplicar a extensão de consulta para adicionar termos relevantes ou corrigir erros de digitação
Para uma lista de itens, agrupar os itens para selecionar apenas um subconjunto relevante pode ajudar
Segmentação de pessoas para extrair roupas
4.2 Codifique a consulta
Depois que os dados relevantes são extraídos da consulta, cada um desses elementos pode ser codificado. A maneira de codificá-lo geralmente é semelhante à maneira como as incorporações dos índices são construídas, mas é possível aplicar técnicas que são relevantes apenas para a consulta.
Por exemplo:
Uma média de vários elementos para obter resultados relevantes para uma lista de itens
Agrapee os pontos da consulta e escolha um cluster como a consulta
Use modelos mais complexos para gerar consultas apropriadas no mesmo espaço, usando modelos de transformador para resposta a perguntas (veja DPR), ou transformações de incorporações de gráficos (veja PBG), por exemplo
Para o caso de uso de recomendação, é possível treinar diretamente um modelo que produzirá as melhores consultas para um determinado objetivo, veja este post do blog do criteo como exemplo.
4.3 Pesquise os índices certos
Dependendo do tipo de consulta, pode ser relevante construir não apenas um índice, mas vários. Por exemplo, se a consulta tiver uma parte de filtro para uma determinada categoria de item, pode fazer sentido construir um índice específico para esse subconjunto de incorporações.
Aqui, selecionar o índice da Toyota tornou possível devolver apenas produtos relevantes desta marca.
4.4 Filtragem de postagens
Construir vários índices é uma maneira de introduzir filtragem rigorosa em um sistema, mas outra maneira é fazer uma grande consulta knn e pós-filtrar os resultados.
Isso pode ser relevante para evitar a construção de muitos índices
4.5 Porção
Finalmente, a construção de um aplicativo de serviço torna possível expor os recursos aos usuários ou outros sistemas. Graças às bibliotecas rápidas de k vizinhos mais próximos, é possível ter latências em milissegundos e milhares de consultas por segundo.
Há muitas opções para construir isso. Dependendo do estado e do escopo dos projetos, diferentes tecnologias fazem sentido:
Para experimentar inicialmente, a construção de um aplicativo de frasco simples com faiss pode ser feita em apenas 20 linhas de código
Usar um servidor adequado com frasco como gunicorn com gevent pode ser suficiente para atingir latências de milissegundos a milhares de qps
Para obter ainda mais desempenho, a construção de um serviço de serviço com linguagens nativas como ferrugem ou C++ pode ser feita. O benefício de usar uma linguagem nativa para esse tipo de aplicativo pode ser evitar custos de GC, já que o próprio índice knn é construído em C++, apenas o código de serviço precisa ser otimizado.
As bibliotecas Aknn são mais frequentemente construídas em c++, mas as ligações podem ser feitas com muitas linguagens (java, python, c#) manualmente ou com swig. Para integração com um aplicativo existente, isso pode ser o mais relevante em alguns casos.
4.6 Avaliação
A avaliação de um sistema de pesquisa semântica dependerá muito do caso de uso real: um sistema de recomendação ou um sistema de recuperação de informações pode ter métricas muito diferentes. As métricas podem ser amplamente divididas em duas categorias: métricas on-line e métricas off-line. As métricas on-line podem ser medidas apenas a partir do uso do sistema, muitas vezes em uma configuração de teste A/B. Para recomendação, em particular, a taxa de cliques ou diretamente a receita pode ser considerada, este documento explica alguns deles com mais detalhes. As métricas off-line podem ser calculadas a partir de conjuntos de dados off-line e exigem alguns rótulos. Esses rótulos podem ser implícitos com base em como os usuários interagem com o sistema (o usuário clicou nesse resultado?) ou explícitos (annotadores que fornecem rótulos). Algumas métricas off-line são gerais para todos os sistemas de recuperação, a página da Wikipedia sobre isso é bastante completa. As métricas frequentemente usadas incluem o recall, que mede o número de documentos relevantes que são recuperados, e o ganho cumulativo descontado que explica a classificação dos itens recuperados.
Antes de fazer análise quantitativa, construir uma ferramenta de visualização e analisar o resultado geralmente fornece insights úteis.
5. Soluções práticas para construir isso facilmente
5.1 Soluções de código aberto de ponta a ponta
Outra maneira de começar a criar aplicativos de pesquisa semântica é usar soluções de código aberto pré-existentes. Recentemente, várias organizações e pessoas os construíram. Eles variam em objetivos, alguns deles são específicos para uma modalidade, alguns deles lidam apenas com a parte knn e alguns tentam implementar tudo em um sistema de pesquisa semântica. Vamos anuná-los.
Jina é um projeto de código aberto de pesquisa semântica de ponta a ponta construído pela empresa de mesmo nome. Não é um único serviço, mas fornece boas APIs em python para definir como criar codificadores e indexadores, e um sistema de configuração YAML para definir fluxos de codificação e pesquisa. Ele propõe encapsular cada parte do sistema em contêineres docker. Dezenas de codificadores já estão disponíveis, e vários indexadores também são construídos em seu sistema. Ele também fornece tutoriais e exemplos sobre como construir sistemas de pesquisa semântica específicos.
Eu recomendo ler o grande post do blog da jina. Sua sintaxe e flexibilidade é o que o torna o mais interessante e poderoso.
Milvus é um serviço de pesquisa semântica focado na indexação, usando faiss e nmslib. Ele fornece recursos como filtragem e adição de novos itens em tempo real. A parte de codificação é deixada principalmente para os usuários fornecerem. Ao integrar várias bibliotecas aknn, ele tenta ser eficiente.
A pesquisa elástica é um banco de dados de indexação clássico, frequentemente usado para indexar categorias e texto. Agora tem uma integração hnsw que fornece indexação automática e uso de todos os outros índices estritos de pesquisa elástica. Se as latências em segundos forem aceitáveis, esta pode ser uma boa escolha.
O Vectorhub fornece muitos codificadores (imagem, áudio, texto, …) e um módulo python fácil de usar para recuperá-los. Tem uma rica documentação sobre a construção de sistemas semânticos e este pode ser um bom ponto de partida para explorar codificadores e aprender mais sobre sistemas semânticos.
Haystack é um sistema de ponta a ponta para resposta a perguntas que usa knn para indexação semântica de parágrafos. Ele se integra a muitos modelos de texto (transformadores de rosto abraço, DPR, …) e vários indexadores para fornecer um pipeline de resposta a perguntas completo e flexível. Isso pode servir como um bom exemplo de um sistema de pesquisa semântica específico de modalidade (rendrondo a perguntas de texto).
Esses projetos são ótimos para começar neste tópico, mas todos eles têm desvantagens. Pode ser em termos de escalabilidade, flexibilidade ou escolha de tecnologia. Para ir além da exploração e pequenos projetos e construir projetos de maior escala ou personalizados, muitas vezes é útil criar sistemas personalizados usando os blocos de construção mencionados aqui.
5.2 Do zero
Escrever um sistema de pesquisa semântica pode parecer uma tarefa enorme devido a todas as diferentes partes que são necessárias. Na prática, a versatilidade e a facilidade de uso das bibliotecas para codificação e indexação tornam possível criar um sistema de ponta a ponta em algumas linhas de código. O repositório de incorporação de imagens que eu construí pode ser uma maneira simples de começar a construir um sistema do zero. Você também pode verificar a pequena palavra knn que eu construí como um exemplo simples. O ajudante PBG que construí com um colega também pode ajudar a inicializar o uso de incorporações de gráficos. Este vídeo do CVPR2020 é outro bom tutorial para começar com isso.
De todos os componentes que apresentei neste post, muitos são opcionais: um sistema simples só precisa de um codificador, um indexador e um serviço de serviço simples.
Escrever um sistema do zero pode ser útil para aprender sobre ele, para experimentação, mas também para integrar tal sistema em um ambiente de produção existente. Segmentar a nuvem pode ser uma boa opção, veja este tutorial do google cloud. Também é possível construir esse tipo de sistema em qualquer tipo de sistema de produção.
6. Conclusão
6.1 Além da pesquisa: aprendizado de representação
Além da construção de sistemas de pesquisa semântica, sistemas de recuperação e incorporações fazem parte do campo mais amplo do aprendizado de representação. O aprendizado de representação é uma nova maneira de construir software, às vezes chamado de software 2.0. As incorporações são as partes centrais das redes neurais profundas: elas representam dados como vetores em muitas camadas para eventualmente prever novas informações.
O aprendizado de representação fornece incorporações para recuperação e pesquisa semântica, mas, em alguns casos, a recuperação também pode ajudar no aprendizado de representação:
Usando a recuperação como parte do treinamento: em vez de pré-gerar exemplos negativos (para um sistema que usa uma perda tripla, por exemplo), um sistema de recuperação pode ser usado diretamente no treinamento (isso pode ser feito, por exemplo, com a integração entre faiss e PyTorch)
Usando a recuperação como uma maneira de criar conjuntos de dados: exemplos semelhantes podem ser recuperados como parte de um pipeline de aumento de dados
6.2 O que vem a seguir?
Como vimos neste post, os sistemas de recuperação são fáceis de construir e realmente poderosos, encorajo você a brincar com eles e pensar em como eles poderiam ser usados para muitos aplicativos e ambientes.
A busca e recuperação semântica são áreas de pesquisa ativas e muitas coisas novas aparecerão nos próximos anos:
Novos codificadores: o conteúdo 3D está sendo desenvolvido rapidamente, tanto com bibliotecas como PyTorch 3d quanto com artigos impressionantes como PIFuHD
A quantificação e a indexação também estão melhorando rapidamente com artigos como Scann e Catalyzer
O treinamento de ponta a ponta e a representação multimodal estão progredindo rapidamente com a visão e a linguagem tendo muito progresso: em direção a uma maneira generalizada de construir qualquer representação?
Onde os sistemas de recuperação podem viver? Até agora, eles eram principalmente localizados em servidores, mas com o progresso do aknn e da quantização, quais aplicativos eles podem desbloquear nos dispositivos do usuário?
Os sistemas de pesquisa semântica também estão progredindo rapidamente: centenas de empresas estão construindo-os, e vários bons sistemas de código aberto estão começando a surgir